

ReSing
音乐制作业需要专业的 AI
我们都知道现在 AI 可以做很多事情了,尤其涉及到数字的虚拟形象生成,比如虚拟人物和虚拟声音等等,其中音乐类的 AI 已经逐步走进了音乐制作行业。但对于我们音乐行业来说,这些 AI 软件有两个最大的问题:
- 一是它脱离了我们的常规工作流。大部分 AI 合成或生成工具,都需要依赖独立的程序或页面,比如最强的 AI 音乐生成系统 Suno,它就需要在网页端或手机上的 APP 端进行创作,我个人很喜欢的本地声音套模软件 Replay 也需要通过它自己的操作界面,这些 AI 软件都严重的脱离了我们以 DAW 为主的工作流,造成了创作断层;
- 二是这类生成软件多是以标准的程序员视角来进行控制,它大多是用参数来调节效果,而非传统的或是专业的音乐类用词,这导致没有任何代码经验的音乐行业者完全无从下手。
这两个原因,造成了现在的 AI 音乐功能和常规的音乐制作并没有形成更紧密的联系。我们在进行音乐创作或制作时,即便想依靠 AI 的帮助,也必须跳出熟悉的 DAW 工作模式,进入一个完全陌生的和带着大量不确定性的代码领域,取得 AI 素材后,又再次回到 DAW 环境,重头对素材进行裁剪修整。
AI 能帮我们干什么?
让我先把话说清楚:我是一个反对利用 AI 来制作乐器分轨的保守派。我用 Suno 用的很溜,对一首歌曲进行 Funk、Reggae、Bossanova 和 Big band swing 的各种 AI 改编玩的不亦乐乎,也深深膜拜 AI 音乐的能力。但我从来不在自己的工程中使用 AI 创作。这是唯一能证明我的价值的地方,而一旦我使用了 AI,我一点价值都没有了。以上是我对 AI 的立场,它比我强太多,但我没办法投降。
那,我会在什么方面没有心理负担的使用 AI 呢?主要是歌曲的范唱和伴唱。
我的很多创作工作会需要范唱,这些通常都由我自己完成,因为创作过程是漫长的,我不可能请一个歌手在工作室待上一天,反复唱几句需要不停修改的乐句。所以我会自己来演唱尤其是伴唱部分。但完全由我恒定的声音来范唱多个声部,听起来显得很怪,因为不管我唱多少轨叠在一起,听起来还是一个人的分身,没有那种不同音域不同胸腔共鸣所产生的群唱的感觉。如果要范唱女声声部那就更加尴尬了。我迫切的需要一款能模拟不同人声的软件,为我这些不同的声部创造出不同的音色,让声音更有丰富。
免费的 Replay?
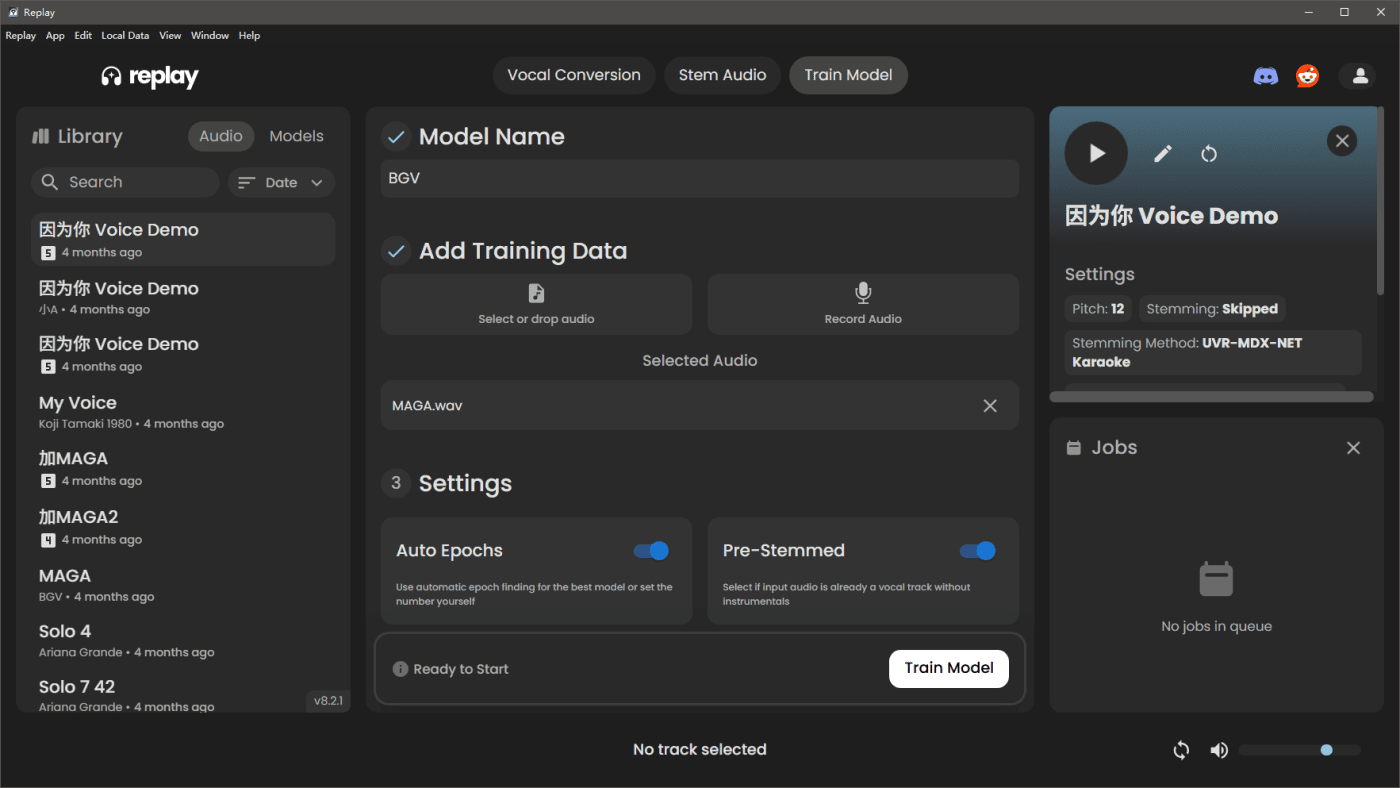
实际上,我之前大量使用 Replay 这款软件,并被它强大的功能所惊艳。我可以在它的界面内传入原始音频,选择模型,然后生成新的音频,甚至由原始的男声音频,改成升高八度的女性模型生成音频。而且它是开放式的,允许我从第三方市场导入用户们自发分享的自制模型,甚至可以做我自己独特的模型。
但它的缺点我前面也提到了,那就是和 DAW 的隔绝。每一次我在 DAW 中对原始音频进行了修改或调整,我必须将新的文件导出,从导出文件夹找到文件,拖入到 Replay,生成,再从生成文件夹找到文件,拖回 DAW,对齐,等等等等。一旦这种工程涉及到 7~8 轨人声,其繁琐和痛苦是可以想象的,关键是,还特别耗时。
一款能载入 DAW 内部的 AI 人声插件成为了切实的刚需。
VoiceAI 和 ReSing ?
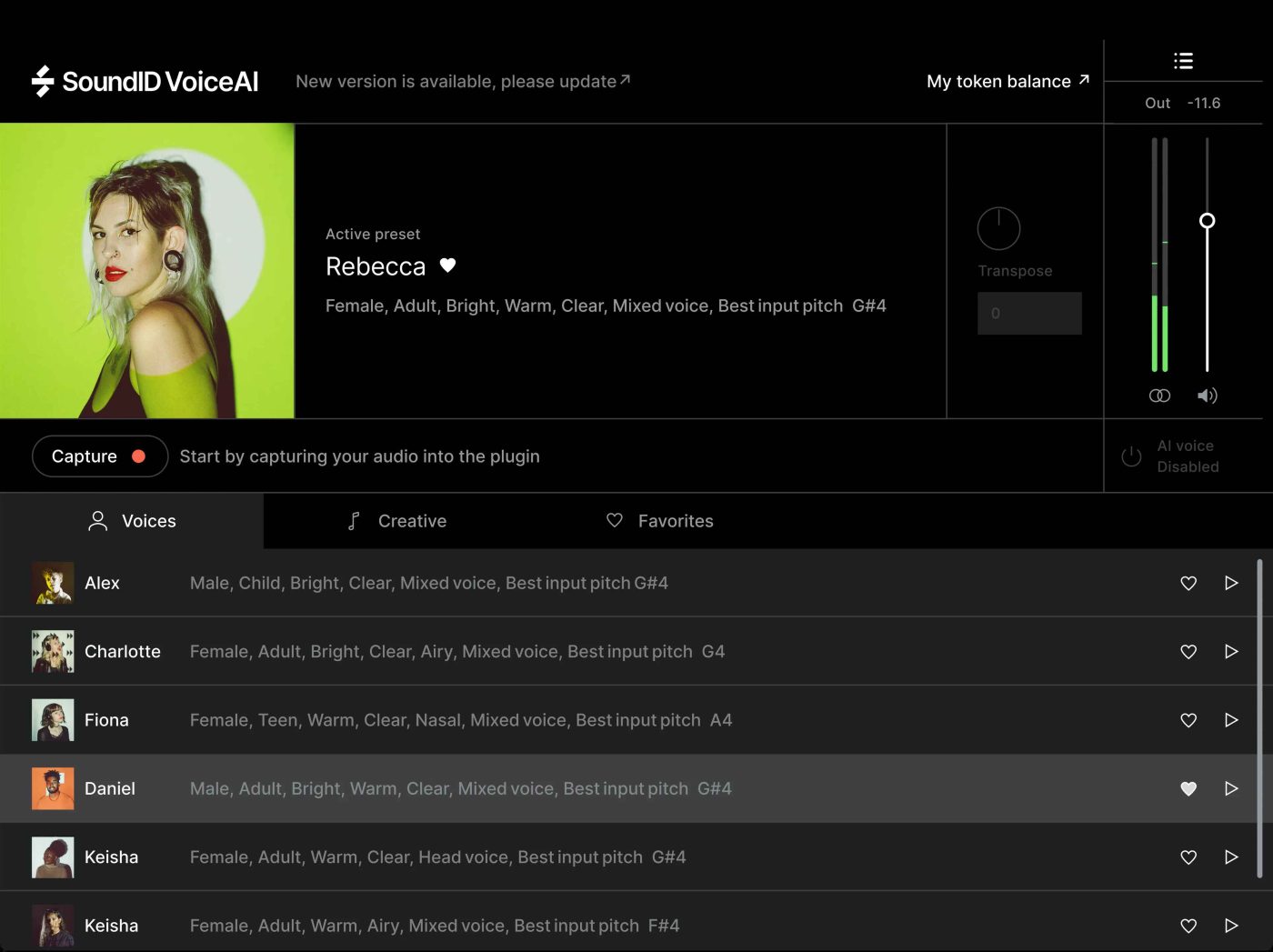
2024 年 4 月的时候,基于嵌入 DAW 式概念的人声生成插件 VoiceAI 诞生了,它是 SoundID(Sonarworks)公司创造的一款以插件形式在 DAW 中实时调用的 AI 音色模型套用程序。
一开始我就被这款可能会改变我制作方式的程序所吸引,并立刻进行了试用。但遗憾的是,感受并不好,试用版有少量的 Token,对音频处理一次就会消耗一定的 Token,然而,它的每次处理都需要将素材提交到 SoundID 的服务器,处理完毕才会发送回来替换原始音频。这意味着出现了两个所有的创作者都讨厌的问题,一是我们的素材被上传,无法保证隐私性;二是它需要保持互联网连接,一旦网络不稳定(尤其是在国内一顿乱封的情况下)我们的项目就无法进行。这都还不是最关键的,我在试用 VoiceAI 时,进行了几次处理,这些处理都扣除了我的 Token,然而处理结果都是失败,我甚至都不知道问题出在哪儿(以我非常善于处理系统问题的经验来说,多半是出在网络连接)。也就是说,VoiceAI 是否有效我根本无从得知,在持续失败的情况下甚至连我的 Token 都扣光了,这是非常糟糕的试用感受。VoiceAI 被我排除出了选项(尽管后来 VoiceAI 也推出了本地化计算,但我对它的第一印象已经破碎)。
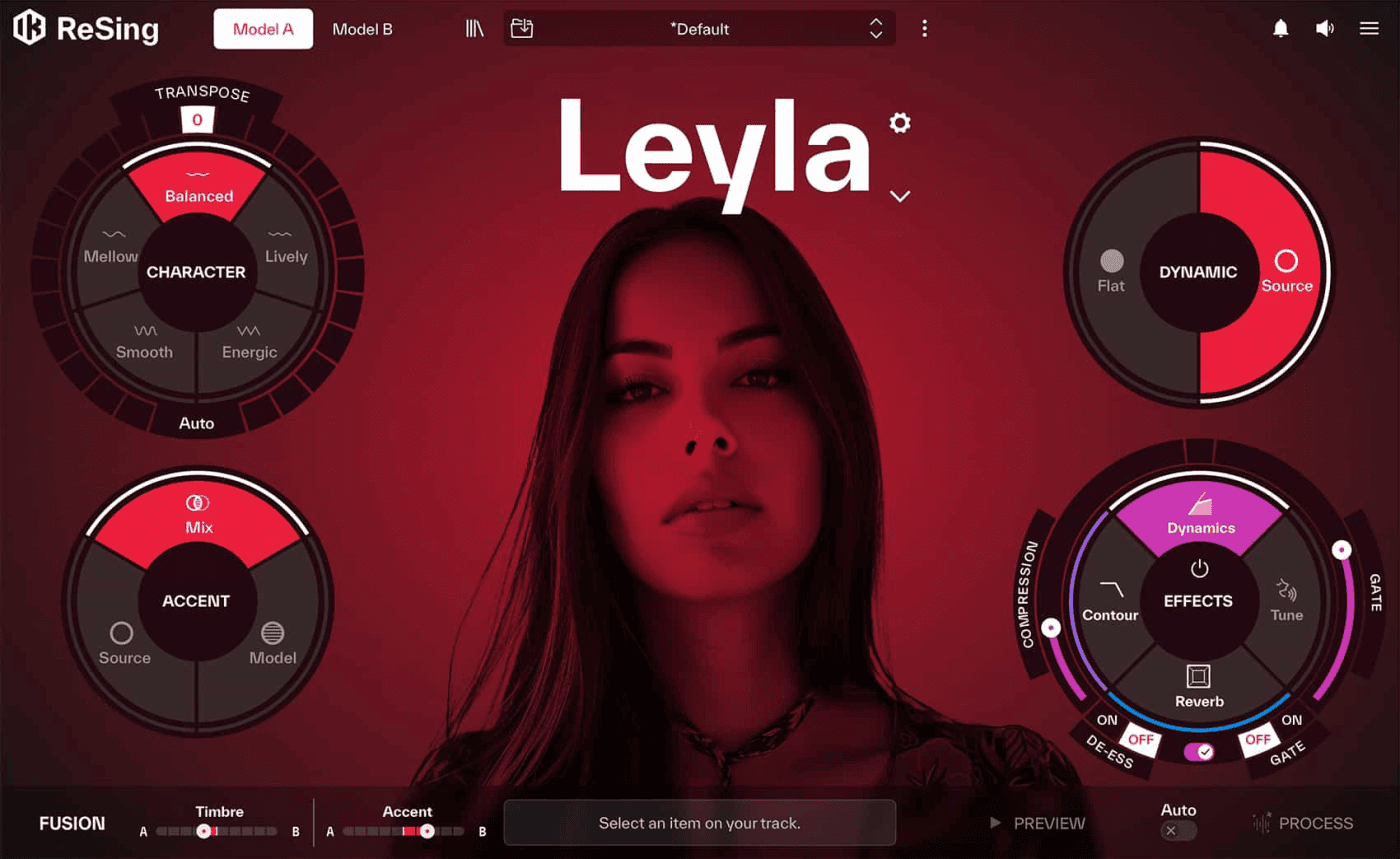
到了 2025 年 9 月,IK 推出了另一款声音生成软件,也就是本文说的 ReSing。而 ReSing 显然学习了 VoiceAI 失败的经验,它一开始就采用的是本地存放模型,和本地化计算,无需保持网络连接,而且它添加了一个付费选项,就是可以无限的生成本地模型。它在发布时就让不少被这些 AI 软件折腾得够呛的制作人看到了一线曙光。它的优点除了大量的可用模型、本地化执行、开放式的模型自制以外,模型声音的大量可控参数,也让呆板的套模变得更加生动和灵活。在它推出的时候,我就表示了对它的极大兴趣,甚至写了一篇新闻推送:新闻!iK Multimedia ReSing – SMPIGGY
最终,我选择了 ReSing。在 6 月 13 日,IK 正好放出了 IKJUNE50 的全场半价活动,我选择了 ReSing 组合中最贵的那个套装:ReSing MAX + Unlimited Model Generation Addon,这套原价 350 美元的套装,以 174 美元的价格拿下。
根据 IK 的页面介绍,这个套装对于自制模型和导入模型没有任何的限制,所以它将是一款可以不断添加模型建造一个庞大的模型库的持续发展中的软件(其他所有规格都有次数或数量限制)。
| 包含的语音 | 包含的乐器 | 模型生成数 | 导入 RVC 模型 | 导入 ReSing 模型 | 许可证期限 | |
|---|---|---|---|---|---|---|
| ReSing FREE | 2 | 2 | – | 1 | – | 永久 |
| ReSing | 10* | 10* | 10 | 10 | – | 永久 |
| ReSing MAX | 25* | 25* | 25 | 无限期 | 无限期 | 永久 |
| Unlimited Model Generation Add-on | 无限期 | 永久 |
就价格来说,哪怕是半价后的 174 美元,依然是相当昂贵的。尤其对于我这种已经非常熟悉 Replay 这款免费软件的操作方式的人来说。但这也就是专业音乐音频人的价值考量,我们看重的是它作为一把更顺手的工具的价值,和它所节约下来的时间成本。如果你爱穿搭,那你一定舍得为了一双漂亮的球鞋或一件外套花钱,换做是爱音乐的人,同理。
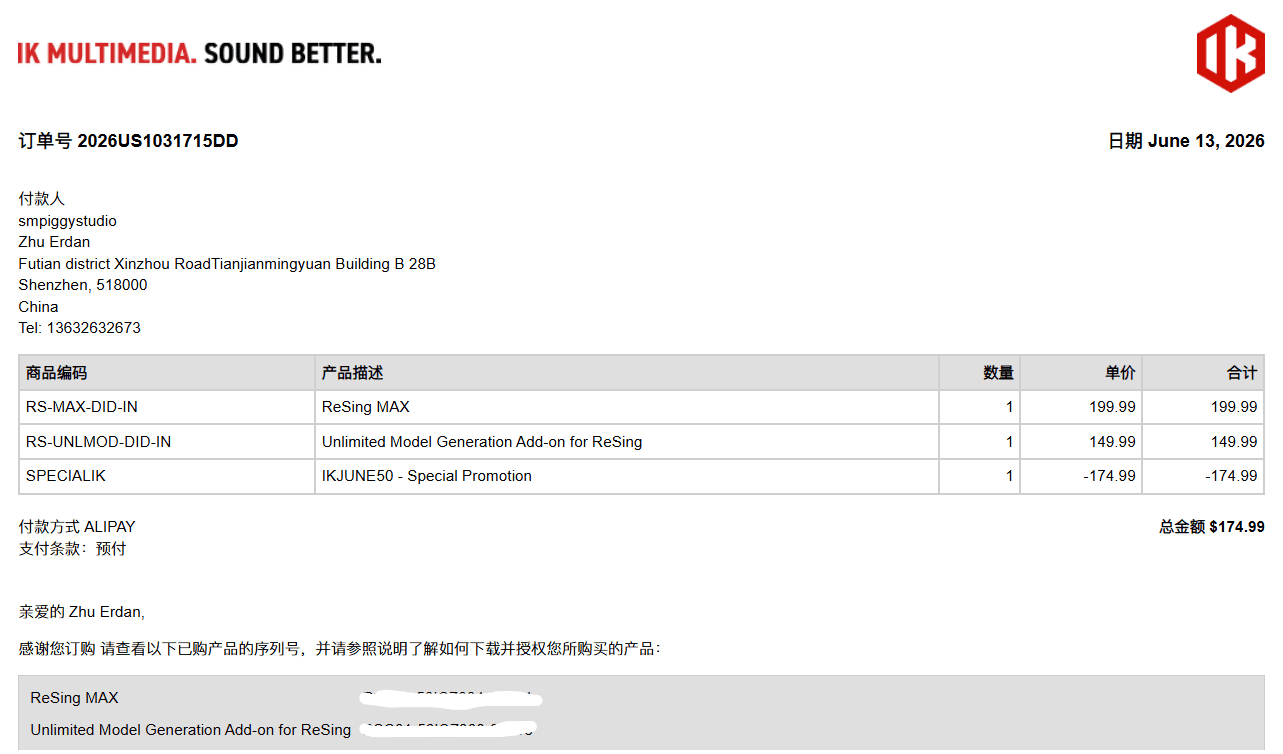
ReSing MAX & Modeler
ReSing MAX 可以使用共 25 个官方模型,及无限次的导入第三方模型。这似乎已经是非常饱和的选项了,但加上这个 Unlimited Model Generation Add-on 的补充包,它支持通过 IK 自家开发的建模软件—— ReSing Modeler 来制作用户的个性化模型,意味着无穷无尽的阿森纳。
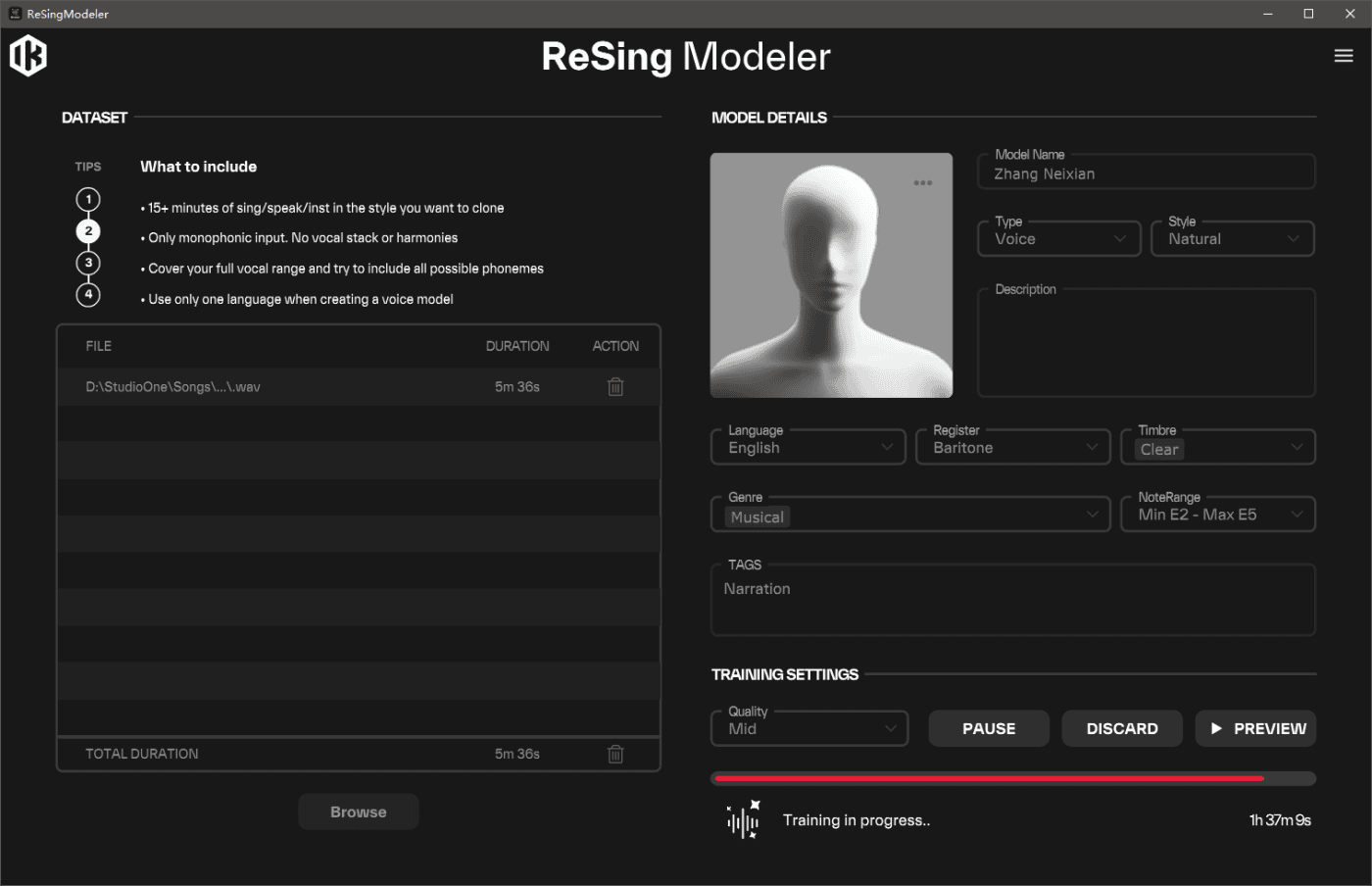
不过在实际应用中,我还没有摸清楚 Modeler 的底细。
我找了一段网络上自媒体节目的纯人声做了下测试。一段 5 分钟的纯人声,在 Modeler 中选择 Mid 级别(一共有 Very High、High、Mid、Low 四个处理级别),用去了我 1 小时 50 分钟的时间。而我试过选择 Very High 级别,结果 20 分钟过去了进度才仅仅过了 1%,而不得不放弃。由于我在网络上包括 IK 的使用说明 PDF 中都找不到这个 Modeler 建模的原理和分级的标准,我只好询问了 Gemini,它告诉我说这很有可能是因为我提供的素材量不够(官方建议是提供至少 15 分钟的素材),导致建模时必须不断自动弥补缺失的部分,从而浪费了大量时间,反正大概就是这么个解释。
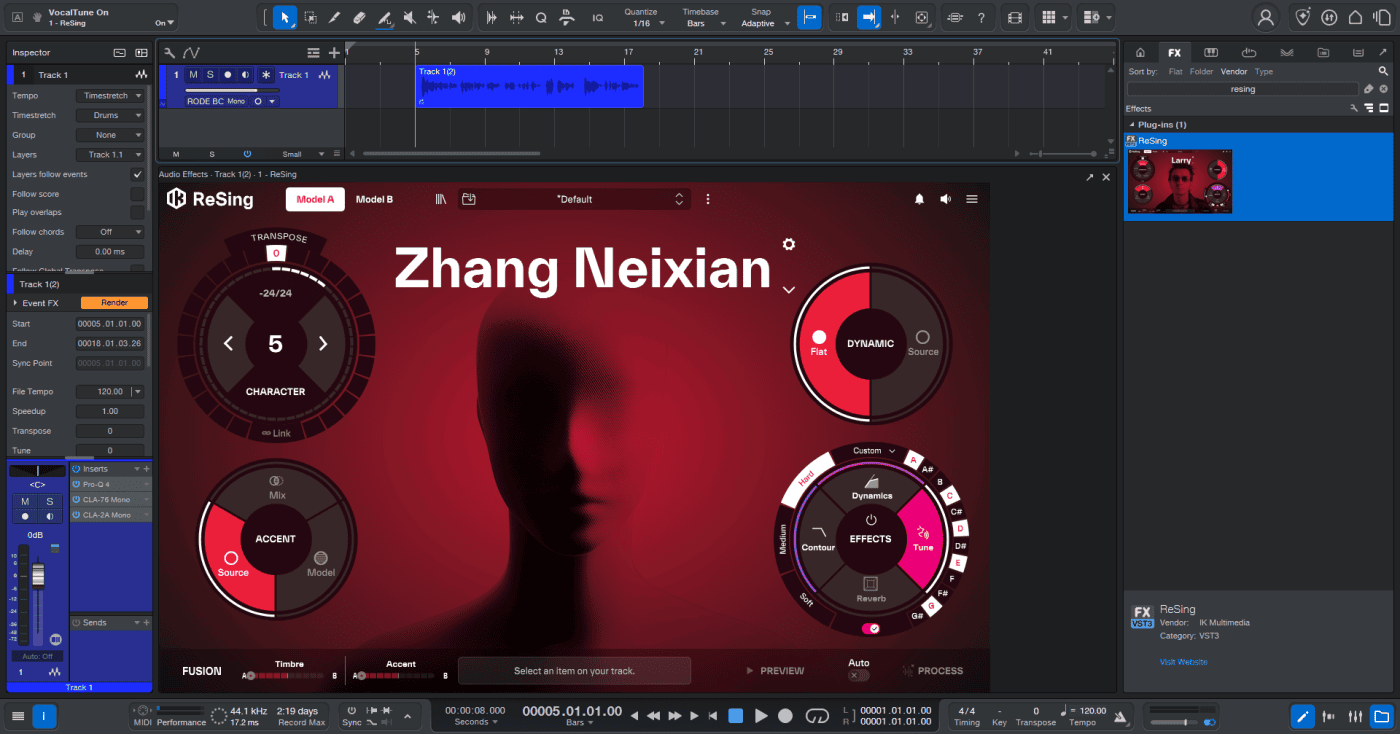
不过好在熬完了这快两小时,我所自建的模型倒是挺顺利的完成了,没有出现任何我担心的意外,我在 DAW 中使用一段原始音频,载入 ARA2 的 ReSing,调入自制的模型,声音如期的变化了。但是,总是带点老外的口音。
ReSing 的优缺点?
ReSing 有一个硕大的调节面板,共有四大项,分别是 Transpose 移调加 Character 个性、Accent 口音、Dynamic 动态、Effects 效果,可以说调节选项确实十分丰富。
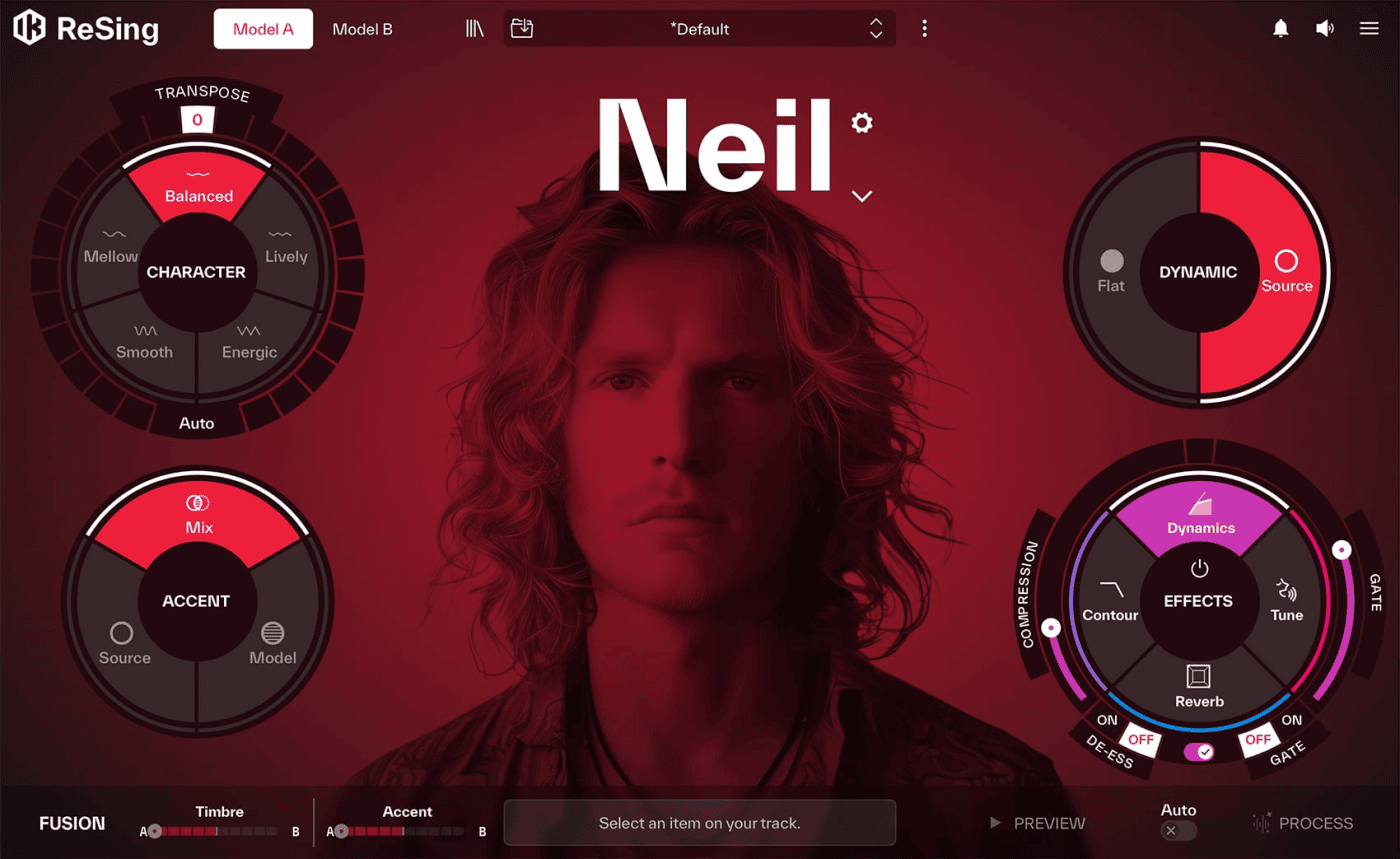
不过在实际应用中我也发现,这些选项中某些调节似乎没有起到明显的大范围的变化,比如右下角的效果选项,除了 Contour 音色轮廓从 Body 到 Air 是可以感觉到明显区别外,其他的调节其实并没有太大的意义,毕竟,ReSing 的设计初衷就是为了让声音可以在 DAW 中进行调节,那,这些混响啊齿音什么的效果,是不是由其他效果器来完成会更好呢?
当然,它也有相当便利性的地方,比如低端控制条的右侧,有个 Auto,这个功能是让我在修改了任意参数后,就自动进行渲染,尽管每次执行调节后要等上两三秒的处理才能听到效果,但确实比每一次都要点击 Process 来的轻松一些。
总之,经过短暂的使用,我总结了 ReSing 一些明显的优缺点,大致如下。
优点:
- 支持独立模式、ARA2 或 VST3 三种形式加载
- 有众多的可选模型。如果用来做伴唱人声的话,可以说这其中大部分音色都可以拿来使用。
- 有丰富的调节界面(可以对模型发音进行详细的设计,如两个八度的高低音,和共 48 格的个性度,可以选择口音来自源素材还是来自模型或来自两者混合,可以选择如源声音的动态还是较平稳的波澜不惊,甚至可以加载两个模型进行不同比例的混合),尽管这些调节效果不是特别明显,但确实有效果
- 进入稳定工作状态后,效率相当高。一段 20 秒的声音,处理速度大概只需要 3 秒钟,关键是全部在 DAW 内部以效果处理的方式完成。不打断工作流,这也是我选择购买 ReSing 的原因
- 可以自制模型
缺点:
- 启动时间较慢(几乎启动需要十多秒钟)
- ARA2 模式下界面无法按不同比例缩放(像 Melodyne 那样可以拉高拉宽自由调节)
- 在 VST3 模式下无法拖拽音轨事件条到 ReSing 的界面上进行处理(也就是说 VST3 模式几乎没什么用)
- 个别模型质量非常粗糙或出乎意料(我选择了一个看起来非常爷们的 John 的模型,然后给我混出来个类似捏着鸭脖子发出来的声音,另一个有着非常 U2 的波洛风格的爷们 Larry,也是一副高了八度的嗓子,这可能和他们的定位都是摇滚歌手有关吧)
- 仅支持导入 RVC V2 版的模型(我之前使用 Replay 时下载过一些 V1 的模型无法被载入)
- 自制建模无法使用个性化照片,无法设置 Epoches 精度
- 仅对英文较为友好。官方模型或自制模型都有一个显著的问题,就是仅支持英语和西班牙语,这意味着只要你使用官模或通过 Modeler 制作的自建模型,说话都带有明显的老外口音,是的,哪怕你明明是用的中文语音素材进行的训练。这导致在对纯语言类的声音处理时,它总是无法找到准确的调调,像极了老外说中文。在演唱方面影响轻微一些。
- 使用 Auto 预览模式要格外小心,由于它的处理有延迟,而我一旦心急多点了几处修改,它可能会出现“Waiting for the AI Engine to complete previous tasks…”的提醒,这时候多半会假死
- 出现过一次 “unable to reach the engine, please restart resing” 的错误,这其实是后台的 ReSing Engine 服务功能死机,但无法在任务管理器找到它,需要强制关闭它重启服务
- 乐器模型几乎没办法使用,比儿童玩具的音色还粗糙难听。也可能是因为我没有选择正确的素材和正确的模型配对。
补充说明
模型转存
ReSing 在首次安装时,需要通过 IK Product Manager 下载安装。而它仅仅官方模型下载就多达 24GB 左右,这些模型文件会默认安装在 C 盘,为捉襟见肘的系统空间平添压力。转存这些文件是当务之急,通过我的这篇文章:速查手册 – SMPIGGY,我们可以通过使用 Link Shell Extension 来将这些模型文件转存到更大空间的 SSD 磁盘中。
运行错误
ReSing 毕竟是一套涉及到复杂的 AI 运算的程序,它并不像我们常用的插件那么简单,插上就用,移除就关,而是它需要在后台调用很多资源,比如 CPU、GPU 以及 RAM 及本地端口等等,这就意味着如果它在后台处理你上一个指令时又收到了你下一个指令,就会崩溃,所以我们要谨慎使用它的 Auto 预览模式。如果 ReSing 出现了因为指令堆积而产生的假死,而我们又无法在任务管理器中找到 ReSingEngine.exe 进行关闭,就需要我们(在 Windows 10 系统中)用如下指令来尝试解决:
1。 使用 cmd 加管理员权限执行命令:netstat -ano | findstr 50000 并回车。此命令会探寻并显示任何使用了 50000 端口的程序 PID,通常来说,使用 50000 端口的一般就是无法关闭的 ReSingEngine.exe 程序。输入命令并回车后,会出来一行字 TCP 0.0.0.0:50000 ……. LISTENING 12345 我们记住这个 PID 值 12345(这个数值每次都会改变,此处的 12345 仅为象征);
2。继续输入命令:tasklist | findstr 12345 并回车。此命令意味着从后台运行程序中找到代号为 12345 的程序,由我们检查是不是 ReSingEngine.exe。通常来说,基本上就是假死的 ReSingEngine.exe 了。
3。确认了是 ReSing 的后台引擎程序后,继续在命令行输入:taskkill /F /PID 12345 并回车。此命令作用是杀死 PID 为 12345 的后台程序,也就是我们一直无法在任务管理器中找到的 ReSingEngine.exe 程序。但是现在,可以被我们的命令行杀死进程了。
4。重新启动 ReSing,或者重新在 DAW 中为音频事件条加载 ARA2 格式的 ReSing,现在它可以正常启动了。
第三方模型
随着 Weights.gg 被 OpenAI 收购,曾经市场上最大的开源自制模型分享社区被永久关闭。现在依然活跃可用的第三方模型站是 Voice Models,它没有 Weights.gg 那样的丰富的页面结构和模型的具体描述,但至少依然有着巨大的模型库和自由下载的便利性。而丰富的第三方模型库,也才是 ReSing Unlimited Model Generation Addon 最大的价值所在。
(当然,我们依然能够使用 Replay 完成在 DAW 之外的所有模型导入或自制等相关的一切工作)
这篇文章写于我购买和使用 ReSing 后的第一天,它肯定还有更多优点或短板等待我发现。如有重大的发现,我会继续更新于此文中。


