音频行业有太多太多的行话和专业术语, 当然这一类的术语解释也是随处可见, 但作为一名制作人, 我也会从自己的角度来积累最常见的术语.
此表单会不断更新和调整

编创类常用术语
Audio Interface 音频接口

音频接口,是电脑与外部音频设备如话筒、电吉他、效果器等模拟输入中间的转换枢纽。音频接口的主要工作, 就是利用内置的A/D(Analog模拟/Digital数字)转换芯片,对输入的模拟信号如话筒、线路输入等电信号进行转换,成为数字形式传输到电脑中,然后由电脑完成后续的数字文件的处理和存储 – 如录制、混音和母带输出(保存为数字音频文件)。与此同时,当电脑播放数字音频时,数字信号传递给音频接口,由音频接口内置的D/A(数/模)转换芯片进行转换,从而变成模拟信号,在输出端由电信号传递给音箱,
我们经常混淆声卡与音频接口,两者功能类似,都是回放声音,但声卡一般安装于电脑内部,因此无法提供专业插口的连接(如话筒所需的XLR插头,及所需的48v幻象电源灯)。而音频接口,通常比普通声卡具有更专业的AD或DA转换功能,比如更高的采样率,更高的位深,更低的失真和底噪,更多的IO(输入和输出)通道,甚至还带有专业的话筒放大器等等。
DAW/Digital Audio Workstation 数字音频工作站
集合编曲, 录音, 混音和输出的专业音频软件, 我们常称之为DAW(D.A.W.或读音:舵).
DAW必须有几个必要元素: 能识别主流专业音频接口; 可使用专业的音频驱动如Core, ASIO等; 可对输入输出Input/Output进行设定; 可与外部设备进行连接; 有音序器区域以用于编曲; 有混音器区域以进行轨道及通道音量的调整; 有专业成熟的内置官方效果器; 支持主流插件格式VST3, AAX等; 可对输出文件格式进行设定等.
要全面发挥出数字音频工作站的实力, 还需要音频硬件如音频接口, MIDI控制器和键盘等, 和音频软件如各类插件, 虚拟乐器等.
MIDI / Musical Instrument Digital Interface 数字乐器接口
这是一种信号传输协议, 由数据线在不同的设备间传输信号, 并激活发音装置以触发声音. MIDI最常见的表现形式是, 用MIDI键盘来触发软件采样器, 软件采样器即时调用硬盘中的音频采样文件, 并加以回放, 从而模仿出现实或非现实乐器的声音. 因此你会常常看到编曲者用MIDI键盘打鼓或弹吉他什么的.
Aftertouch 触后
触后是一种MIDI输入设备的附加功能,即按下琴键后继续施加不同的压力,MIDI设备可以将这个压力变化的曲线持续发送到发声设备,以让声音也随之变化,前提是发声设备也支持Aftertouch参数。
Pitch Wheel/Mod Wheel 弯音轮/调制轮
MIDI输入设备比如MIDI键盘,通常会带有两个可滚动的推轮,一个为PItch Wheel弯音轮,可以控制发声乐器的音高,一个为Mod Wheel调制轮,用来控制发声乐器的特殊参数,默认情况下Mod Wheel作为颤音轮使用。
Pedal 踏板
在MIDI制作的语境中,踏板通常分为三类,开关式,渐变式和升降式。开关式踏板通常用于开启和关闭效果,比如用来添加声音的延音。渐变式踏板拥有一个从0~127参数的渐变,通常用来控制音量或其他线性参数。升降式踏板类似于渐变,但它会自动回到中间位置,这类踏板类似于弯音轮,适合控制声音效果的正负变化。
Pad 打击垫或者铺垫音
Pad在不同语境中可以表示不同含义,在电声乐器或音色中,Pad通常表示为铺垫音,意为音色柔和空灵的背景音。而在MIDI输入设备上,Pad表示打击垫,也就是一个个用橡胶做成的可敲击的方块,常用来模拟打击乐的手感。实际上在音频术语中,Pad还有一个含义,即在话筒放大器上,PAD是Passive Attenuation Device的缩写,意即被动式衰减装置的意思,通常为一个开关或按钮,作用是将过大的话放音量强行衰减一定的级别(试话放厂家参数而定)。
Sequencer 音序器
音序器是DAW的主要功能. 由于音乐与音频都是时间的艺术, 因此多个声音(也就是信号)需要直观的排列方式, 和有序的发声先后, 这就需要依附于一个纵横向的界面, 这个界面称为Sequencer 音序器.
音序器通过添加不同的Track, 可以记录包含MIDI音符, 音频片段, 音量曲线和自动化曲线等信息. 这些不同类型的信息需要不同的记录或处理方式, 就需要使用相应的Track轨道来记录. MIDI信息需要MIDI轨, 音频片段需要音频轨等等. 许多轨道层叠着排列下来, 就成为了我们所说的多轨Multi-Track. 在多轨中, 我们修改这些信息的位置, 进行编排, 从而完成编曲.
Track 轨道
在音序器中, 轨道是用来记录和排列内容信息的地方, 比如音频内容, MIDI内容, 速度曲线等等. 我们需要为Track指定声音的来源, 才能录制音频或MIDI的片段, 而这就需要接入声音或MIDI通道, Channel. 要记住, Track仅限于在音序器中, 起到记录和排列信息的作用.
Tracking 跟录
Tracking跟录, 基本上就是Recording录制, 当然, 也有认为Tracking还包含了实时的不断控制的行为, 比如在录制中不断调整输入和音量的行为, 而认为Recording含义更为单调, 包含较少的控制行为. 这些区别都基于语境, 大体上两者并无差别.
Mixer 混音器
音序器可以管理声音内容的排列, 但无法直观的控制多个信号的强弱. 我们按电脑键盘的F3键(大部分DAW支持), 会打开混音器Mixer, 也叫混音面板. 音序器中所有能发出声音信号的轨道, 在这里都占有一个通道Channel. 这些通道以垂直的竖条显示, 并行排列, 从而组成了我们的多通道Multi-Channel混音器.
在这里, 我们可以全心专注于声音的调整与混合, 比如调整它们的声像从而改变它们在听觉中的左右分布, 调整它们的音量推子来平衡不同声音的融合, 并通过混音器最右侧的总输出, 来监听所有通道的信号.
Channel/CH 通道
通道是信号的物理输入和输出端口, 类似于路由. 初学者常常被Channel通道与Track轨道搞糊涂, 简单来说, Track轨道是用来记录Channel通道中传输的具体内容, 而Channel通道仅用来连接或分配信号的输入与输出. 比如一位歌手通过一只话筒演唱了一段旋律, Track就用来记录这段音频信息, 而Channel则表示这只话筒接入音频接口的端口是哪个. 我们可以创建多个Track, 来记录这一只话筒的信息, 但这只话筒所使用的物理Channel, 永远只有一个.
记住这一点, 通道是物理地址, 轨道记录信息. 轨道指定到一个输入通道, 就可以记录这个通道上的声音信息. 而轨道再指定一个输出通道, 就可以将声音信息从指定的通道发送出去, 从而让我们听到声响.
In(Input)/Out(Output) 输入/输出
当你观察你的声卡或音频接口, 你会发现它的前面板会有一两个输入接口Input, 而后背板也会有两个或更多Output. Input通常用来接入外部发声设备, 比如话筒, 吉他, 合成器等, 而Output则用来通过连接到耳机和音箱, 发出声音.
前面的词条我们知道了轨道Track和通道Channel的区别, 而In和Out也是我们需要理解的一点. 继续以一位歌手的话筒为例, 她的话筒插入到了音频接口的CH1 Input, 在DAW中, 我们添加一条轨道, 将轨道的输入指定为音频接口的CH1 Input, 这样我们就能在这个轨道上录制来自这个话筒的声音. 同时, 我们会发现在DAW的混音器中, 也被添加了一个通道, Output被指向了Main Output, 也就是主输出, 我们通过主输出听到了刚才录制的声音. 为了提高效率, DAW会为所有新建的轨道, 指定默认的输出通道为主输出, Main Output. 这样我们不必在添加了一条轨道后, 在给它指定输入后, 还要给它指定输出.
Bus 编组/总线
我们知道, 通道将信号传递到DAW的主输出中. 但是, 在大型编排制作中, 几十上百个轨道所相对应的几十上百个通道, 在后期混音时会产生极大的混乱. 那么, 对通道的管理显得尤为重要. 如何管理无数的通道呢? Bus 编组. 编组的作用, 就是在通道和主输出中, 再添加一层管理, 可以将多个通道包含其各自的信号, 编入编组. 编组混合这些信号后凝聚成一个新的信号, 再传递给主输出. 编组和通道几乎一模一样, 同样有Inserts插入区, Sends发送区和Volume/Pan音量声像控制区, 唯一不同的就是通道只能有一个信号输入和一个信号输出, 而编组是多个信号输入, 和一个信号输出. 这也决定了编组可以吸纳多个通道信号并混合为一个信号的作用.
比如大型的管弦乐作品, 我们可以把各个弦乐声部(小提琴, 中提琴, 大提琴, 低音提琴)等各个通道, 进行简单的比例调整后, 统一编入一个弦乐编组, 将铜管(小号, 长号, 圆号, 大号)通道, 调整后编入一个铜管编组等. 后期进行混音时, 只需要控制弦乐和铜管两个编组就能完成快速的混音了. 而到了具体声部如小提琴的微调时, 我们再进入弦乐编组下的小提琴通道, 反复调整即可. Bus编组大大的提升了混音效率.
Group 建群
编组的出现, 让信号混合成为可能. 但因此也就出现了另一种需求, 即, 可以统一管理指定通道, 但不对其信号进行混合, 这就是Group建群. Group建群, 可以将多个通道进行绑定, 对群中的任一通道进行任何操作, 群内的其他通道也会响应同样的操作. 比如调整群内某一通道的音量推子, 其他通道音量推子也会做出相同反应. 或是为某一通道添加效果器, 其他通道也会批量添加同一效果器等.
Plugin 插件
我们知道DAW是一个庞大的系统,用来协调各种信息的分配和编辑,从而制造出音乐。然而DAW一般都不是全能的,在某些领域我们还需要安装一些小而专精的软件,来帮助DAW实现特定的处理。这些拥有特殊能力,但依附于DAW运行的软件,我们称之为插件 – Plugin。当然,DAW自己也会有很多处理特定任务的插件,这类自带的插件我们称之为Stock Plugins,而安装的其他品牌的插件,我们称之为The 3rd Party Plugins 第三方插件。
Plugin 插件包含两种形态:一种是音频效果器类的,主要以EQ、压缩、混响等形式存在;另一种是虚拟乐器类的,比如软件合成器、软件采样器、虚拟架子鼓、虚拟钢琴等。有很多著名的品牌专门制作第三方效果器插件,提供给各式各样的DAW和全球的用户使用,如Waves \ iZotope \ UAD 等等。而专门制作第三方虚拟乐器插件的品牌有NI、Arturia、XLN Audio、Xfer Audio等。
VST3 / AU / AAX / CLAP / ARA 插件格式

VST3 是Windows和MacOSX通用的最新的插件格式。AU则专用于Mac,AAX则专用于Pro Tools(一款著名的DAW)。CLAP是一款最新的插件格式,它能更有效的利用CPU效能,同时对MIDI控制进行了更深入的扩展,目前已经有不少DAW和第三方插件品牌在尝试这个新的格式。
ARA 则是另一种目前更先进的格式,全称为Audio Random Access,音频随机访问。这个格式的特点是能在非常快的时间内读取音频的所有信息,并保存数据1常规的插件格式只有临时的短暂的数据流,提供我们对音频的全面的编辑能力,因此ARA技术一般由一些音频编辑类插件使用,如修改音高的Melodyne、RePitch等等。
VST 虚拟效果器
VST是由Steinberg公司开发的通用插件技术, 同时也是目前最流行的插件格式标准, 即各类软件开发厂商, 以VST的代码格式制作插件, 而各大DAW厂商也加入对VST格式的识别, 从而创造一个更积极开放的插件生态. 目前的主流插件和DAW都支持以”DLL”为后缀的第二代VST, 和以”vst3″为后缀的第三代VST, 也称VST3.
当然, VST并不是当前唯一的插件格式, 苹果系统就支持AAX格式, 一些新兴的格式如CLAP等也正在测试中, 它们会以更低的资源占用, 更快的响应等成为更优秀的继任者.
VSTi 虚拟乐器
VSTi, 是VST Instrument的简称, 得益于VST创造出的可以应用于不同DAW宿主内的通用的插件生态, VSTi更进一步, 利用这种插件形式, 将更大型更复杂的音色合成乐器以插件形式植入DAW进行应用. 和VST一样, VSTi乐器目前也已发展到VST3格式.
VOX / Vocal / Voice 人声
它们都用来代表人声
Lead 主音
Lead一般代表乐队中演奏演唱主旋律的声部。它可以是电吉他 Lead Guitar 或人声 Lead Vocal 或一切明亮有穿透力的乐器。这也是为什么我们会在合成器中大量看到这个类型,其所包含的音色通常都明亮且响亮。
与Lead相反的类型就是Backgroud,背景音。比如BGV,全称就是Background Vocal,背景人声或伴唱人声。
Instrumental 器乐/伴奏
器乐部分, 或伴奏版本. 如果你需要寻找英文歌曲的伴奏, 试着在歌名后面加上Instrumental.
Sampling 采样技术
采样技术是目前主流的在软件上重现真实乐器声音的技术. 采样技术利用录制真实乐器或其他声音的声音样本, 并逐一编入回放设备中, 得以在软件环境下重现声音. 这一方式目前已经覆盖了几乎所有音乐制作产业, 令创造音乐不再需要耗费大量的人力物力. 从影视音效, 到人声合唱, 再到数字混响读取的脉冲文件, 采样技术是当前音乐制作中不可或缺的重要成份, 从恢弘的交响乐, 到嘻哈音乐中的鼓组, 你听到的可能全部都来自于采样音色的重组.
可以进行采样编辑和回放的硬件和软件都被称为Sampler采样器, 目前最主流的采样器为NI公司的Kontake. 采样在通过采样器制作并包装后, 便成为Sample Library采样库或音色库.
Sampling中一般常见的技术,就是单音单层单采,单音多层多采或多音单层单采多音多层多采。单音单层单采指的是乐器每演奏一个音高使用一个单一力度进行一次采样(意味着在这个音高上无论如何用力弹奏都只演奏同一个样本,音色较为单调);单音多层多采是每个音高已不同力度进行多次采样(不同力度可以分配到MIDI响应中,以不同的力度弹奏琴键可以触发相应力度层的采样,音色更真实;而每个力度层也可能使用多采,使即使是同一力度下演奏触发的样本,也能在多个同力度下的样本中轮换,音色更为真实),多音单层单采就较为简单,对乐器的一个音高进行采样,然后不分力度层的将样本放置在不同的音高上,通过音高数字调整,让它变形为符合音高的变化,但实际演奏中,这样单一的样本很容易被人听出空洞和MIDI感,如果快速的重复此音还会出现机关枪效应2即音色如机器般的重复,非常缺乏真实感和戏剧性,早期的MIDI采样正是这种方式制作的)。
Sampling的另一个技术就是Round Robin,轮播。前面说到的单层多采了,即一个力度层也有多个采样,这样用户在演奏时,即使使用同样的力度,每次听到的也是不一样的声音。轮播制,是将多个采样规划后,按打乱的出场顺序,让采样乱序的播放,这样既有随机性,又不会出现饥饿问题(不同于Random 随机模式,随机模式中会有个别采样可能长期得不到播放机会,这就是饥饿问题,这就会降低音色的丰富性)。我们要记住,Round Robin不是Random。Round Robin是在每一个循环中都乱序演示所有的采样,演示完毕后下一个循环以新的乱序再演奏,以此类推。而Random 随机则是不分循环一直随机下去,可能导致某个采样多次出现,而某个采样长时间不出现。
Modeling 建模技术
在音频领域中, 建模技术是通过软件编程, 模仿硬件内部电路特性, 或模仿乐器的物理震动特性, 从而在软件层面重现硬件或乐器的声学特性. 我们所看到的许多经典硬件的软件复刻版, 即是这种建模技术的运用成果. 而在乐器层面, 除开之前说过的采样技术, 建模技术也是非常新兴的声音再现途径之一. 通过对乐器从结构, 金属组件, 丝弦特点, 共振频率等特点区域的建模, 可在使用时让这些模块实时生成极其接近真实的乐器声音. 建模音色的最大优势, 就是通过CPU实时合成声音, 而不再需要采样音色庞大的资源存储量. 目前在建模音色方面, 通过对大量合成器的复刻, Arturia的技术首屈一指.
建模技术在模仿基于电路和数字化的设备方面有先天优势, 而采样技术在真实再现现实声学方面更有得天独厚的技术领先.
Transpose/Octave 移调/八度
Transpose移调, 常见于MIDI事件的选项, 用来以半音为单位, 以”+, -“来上下调整. 当移调涉及到12个半音, 就到了一个Octave八度(八度就正好是十二个半音).
BPM(Beat Per Minute) 每分钟节拍数
任何DAW或音序器, 都基于BPM. 一般一个成年人快步行走的速度为每秒2步, 这个速度大概就在120BPM左右. 由此也可判断, 80BPM的速度比较舒缓, 而140BPM则显得急促躁动(这也是为什么一些激烈的电音音乐速度多在140BPM).
为什么音乐中的速度要基于分钟?因为读秒是所有人都能建立的速度概念,或多或少。一分钟等于60秒,就等同于音乐速度的60 BPM,这样我们在看到这个速度标识时,就会有大致的速度概念。
Loop 循环
流行歌曲常用的一种循环素材形式。长度在2小节到4小节不等,更长的也有8小节的,由于其偶数性,适用于大多数音乐的结构形式。因此可以反复循环,可以是鼓点或乐器的重复节奏型,以建立音乐的稳定性与流动感。
Groove 律动
存在于整首乐曲中的律动感,可以是轻微的切分音感觉,或强弱上的不平衡感,Groove可以是带点摇摆感的Swing,或是强弱分明的Tango,或是全部押在后半拍的Bossanova等等。只要音乐能让人听着像晃腿,那这音乐就有Groove。
Beat / Beats 这个没有确切的翻译词汇,就叫做Beat或Beats
传统的音乐编配是以旋律和和声为首要元素,围绕它们而定制,因此在和声与段落结构都为旋律服务,并用各种方式填补旋律之余的空缺。而现在更为流行的电音类音乐中,出现了很多需要以音乐为基底进行二度创作的歌手,他们本身并不编创音乐,而是在听到音乐伴奏后激发编写歌词的灵感,也就是说,他们先需要得到音乐基底,才能完成作品。这就恰好与传统的音乐创作方式相反。这也就意味着市场开始大量需求半完成品,这类音乐中已经预置好了强烈的节奏,AB段的结构,非常简单但抓耳的和声进行,只需要加入有节奏感也能配合和声进行的人声,就可以当做成品。在这个需求下,便出现了Beat making这个行业,Beatmaker们非常熟悉电音的编创,能创造出强劲有力的伴奏,统称Beats,这些Beats会在网络上进行售卖。而流行歌手们购买这些Beats的二创权和使用权,就可以快速在网络平台展示自己的大量作品。
但,我们知道这些音乐真正的灵魂归属是谁。
Vibe 氛围
氛围包含Groove也就是律动,还包含整个的音乐气氛如松散的电钢琴,或者某些抒情的旋律等等。它多指音乐所创造的一种意境或氛围。
Fill 填充
某些乐句乐段在多次重复时会显得单调,通常编曲者会习惯在两次重复中间尤其是前半句的句末(也可以是段末),添加一些随机或新的元素,来增强新鲜感。常见的是加入一些鼓的片段Drum Fill,也可以用其他乐器或方式填充。
Build Up 堆叠
你要说是建立也行, 是一个意思. 大体上, 是对当前旋律或织体的叠加. 比如加入低八度的乐器对旋律进行重复, 或从8分音符的鼓点加密到32分音符的鼓点, 从空间和时间上对音乐进行加厚加密. 这个手法常见于电音舞曲.
Break / Break Down / Drop 中断/掉落
当堆叠填的越来越满时,听觉上就容易产生厌倦感,编曲者这时候会加入一个Break,让众多声部平息,制造出瞬间的空灵感增强听觉对比。在电音舞曲中,先层层堆叠再突然中断(或掉落)的手法也会让听众非常的兴奋。
Intro / Verse / Chorus / Bridge 前奏/主歌/副歌/过渡
常见的歌曲结构名词。比如歌曲结构可以为。Intro – Verse – Chorus – Verse – Chorus – Bridge – Chorus – Chorus。但所有人都可以按自己的想法来安排。
Stem 分轨
Stem是一首音乐中各个声部的单独音频文件。由于现在音乐制作中已经简化了大量环节,我们通常处于边创作边混音的模式。而在分类更完善的音乐制作流程中,编创和混音往往是由该领域的专业人员分别完成,这就需要编创者将音频素材转交给混音师完成混音步骤。由于MIDI乐器需要读取不同系统上的音色才能发声,因此编创者将包含了MIDI文件的工程文件给混音师,并不一定能忠实再现编创者系统上的声音效果。这就需要编创者先在自己的系统中将各个声部单独导出为音频文件,即Stem后,再交接给混音师也保证声音的完整性。
Stem和Track意义上有相同之处,也有不同之处。Stem可能包含多个Track内容的合成,而Track通常仅代表一个声部。同时,Stem也更具象化的表示当前阶段,即音乐即将进入混音阶段。
现在也有软件可以对合成后的音乐进行拆混,即智能分析音乐中的成份,推断出不同的声部,随后拆解混音,将其拆为Stem分轨,比如Studio One 7中新增的Stem Separation分轨分离,或SpectraLayer中的Unmix拆混等。但其成品效果见仁见智。

音频类常用术语
ADSR
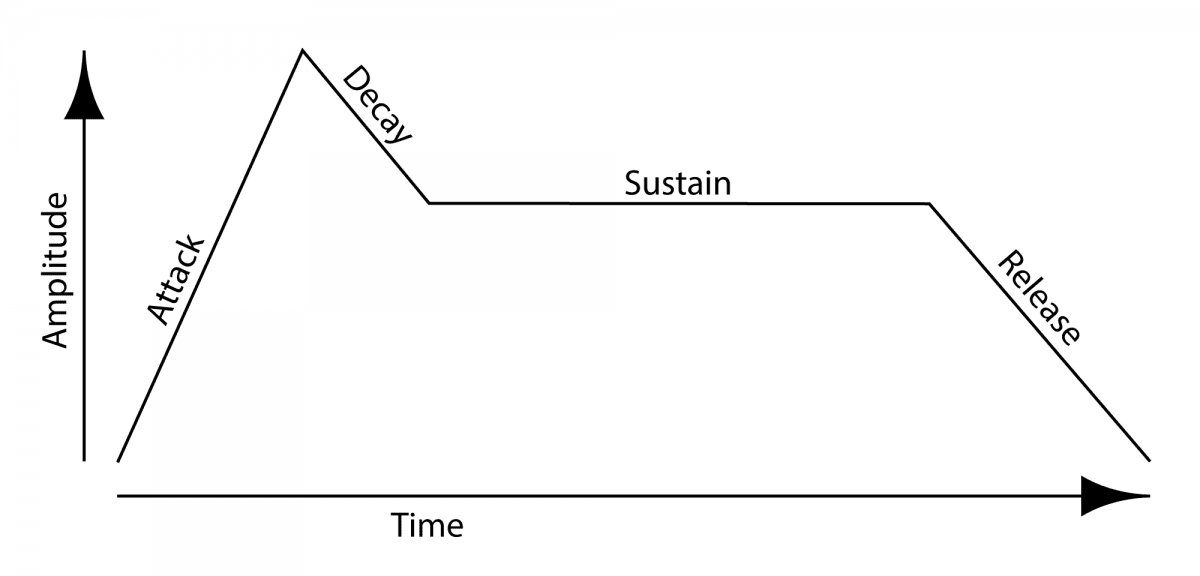
这个缩写是我们最开始接触音频时, 都必须了解的. ADSR是一个声音的最原始形态, 它包含了A-Attack音头, D-Decay衰减, S-Sustain延续, 和R-Release释放.
Envelope 包络
包络是一段音频的变化形态. 我们常见的包络形态是音频的振幅, 即音频有小到大或反之的不断变化的曲线. 但包括也可以是音高的曲线变化或频率的频响曲线等等.
Amplitude 振幅
只代表音频音量变化的包络, 就成为振幅. 振幅不仅在视觉上可以提供大致的音频的响度和音量变化信息, 还可以作为一个参数, 用于某些效果器中, 通过振幅的变化, 自动改变效果器的某些参数. 注意, 由IK Multimedia出品的一款吉他效果器叫做Amplitube, 而非Amplitude.
Bit 位深
玩过任天堂红白机的朋友, 对8位游戏机这个概念应该毫不陌生. 从8位到16位, 再到现在的次时代, 位数的翻倍远比数字上看起来的更加夸张. 音频也是如此, 从普通的16位录音, 再到24位, 现在已经出现了32位录音标准, 而音频位数的升级, 意味着巨大的宽容度的提升, 录音很难再出现过载和爆音的现象了.
Sample Rate 采样率
采样率主要出现于录音规格中. 我们知道, 在数字领域中, 一切都以精度作为转化模拟信号到数字信号的标准. 而数字录音中, 这个精度就是采样率, 即每秒对音频进行的切片数量. 目前通用的基础采样率是44.1KHz(千赫兹)~48KHz, 更高精度的采样率从96~192KHz都有, 但常规的音乐制作或录音并不需要这么高的采样率, 因为对于人耳, 过高的精度并不能靠听觉分辨出来.
Volume 音量
音量是音频振幅不断变化时, 相应的响度值的变化. 音量不会改变音频的特性, 只是按比例提升或缩减.
Gain 增益
如果你刚刚接触音频领域, 你可能会被搞晕了, 这明明就是个音量旋钮. 其实不是. 增益常用在需要接入外部录音设备的声卡或音频接口上, 以提升音频信号. 增益更像是一个功率放大器, 不断的提升数值, 会让设备逐渐全力运作从而不断强化通过的音频信号. 这意味着, 增益加大会不断提升音频音量, 没错, 但也会不断改变音频的质感(因为内部电气功率的不断放大), 过度放大增益还会造成失真(音频电气化)同时提升很多电气噪音(统称底噪). 因此Gain增益是一个需要小心控制的环节. 如果说音量是一个物理概念, 那么增益可能偏向于化学概念.
*同时, 也要了解, 现在不少DAW也在轨道上添加了Gain调节选项, 意味着一个轨道可以有Gain和Volume两个针对音频信号调节的参数. 但DAW中的Gain不同于其他硬件设备上的Gain, 由于DAW基于数字化, 这个Gain主要用来帮助调节音量, 但不会添加任何硬件类的化学效应. 一些以模拟硬件为设计方向的插件(软件)的Gain会增加硬件属性, 但纯数字化插件则纯粹是信号补偿和音量辅助.
Noise Floor 底噪
虽然我们都称现在为数字音频时代, 但这只是表示音频的记录和编辑方式是数字化的, 但音频的收录方式, 依然需要由各类电子元气件, 电压和电流组成. 而一旦存在电气元素, 就会有音频的噪音信号, 这些信号组成在一起形成底噪, 混合着话筒录制的声音, 同时被传输进录音装置. 不过通常情况下, 这些底噪已经被设备厂家尽力控制在最低, 因此, 你可以通过提高音频信号的增益, 来实现和底噪的强弱对比达到听觉上的忽略不计. 但依然, 要小心控制增益, 避免让音频出现不必要的失真.
Headroom 头部空间
音频是动态的, 而数字录音是有限度的(不得超过0db). 这意味着我们需要在有限的框架内, 要为声音的动态预留一定的空间, 以免瞬态音量超过了0db从而造成数字失真. 我们为这种瞬态预留的空间, 就叫做Headroom头部空间.
Gain Staging 增益调平
了解了上面两个词条, Noise Floor和Headroom, 我们会发现, 数字录音给了我们很大的限制, 音频的增益既不能太低, 不然难以与底噪区分开来, 又不能太高, 不然容易冲破头部空间造成失真. 因此我们需要仔细的寻找一个增益的平衡点, 来录制较为完美的音频, 它最好干净, 饱满, 有漂亮的峰值曲线. 这个寻找平衡点的过程, 就是Gain Staging增益调平.
Mute/Solo 静音/独奏
Armed 预备录音
Filter 滤波器
滤波器常用于快速控制音频的基础频率曲线. 使用滤波器可以对所在的频率进行削弱, 切除等操作. 比如调音台常见的HPF, 就是High Pass Filter, 高通滤波器的简称, 意味着这个开关将切除指定的低频, 只允许高频通过. 滤波器更高级的形态, 就是EQ.
Dynamic Range 动态范围
动态范围可以包含很多领域. 一条人声音频的波峰到波谷的db差, 可以叫动态范围. 一首完成的歌曲从开始到结束的平均响度差也可以称为动态范围. 一首交响乐的动态范围可以在20~30db, 而一首流行音乐的动态范围通常在8db上下. 动态范围小, 意味着持续的响度大, 但音乐性和戏剧化就会减少. 因此, 准确的控制你的音乐动态范围, 在它和响度中找到平衡, 是音频后期的重点之一.
Compressor 压缩器
控制动态范围的方式, 就是不停的控制音频的音量. 而控制音频音量最常见的用法, 就是为它添加压缩器Compressor. 当音频通过压缩器时, 压缩器侦测音频的信号, 并通过内置的阈值来决定, 当音频信号大于阈值时就对超过的音量进行压缩, 当音频信号低于阈值时就不做限制让它通过. 这样音频信号的音量在突然变大时, 就会被压缩器所控制变得较弱, 从而使整个音频的音量保持在一个较为稳定的范围中. 处理阈值以上的信号并将它向下压缩的, 叫做下行压缩Downward Compression, 也是压缩器最常见的形态. 而某些压缩器还可以进行上行压缩, Upward Compression, 这时候该压缩器则是处理阈值以下的信号, 并按设定比率将弱信号提升到阈值附近, 这种压缩形式并不多见, 因为它常常和扩展器的默认功能产生混淆.
Expander 扩展器
和压缩相反, 扩展器是另一种控制动态的方法. 扩展器使用的是完全和压缩器相反的方式, 即反向处理阈值上下的音频信号. 比如我们默认的压缩, 前面说过, 是处理阈值以上音频信号并将它压低的下行压缩, 那么默认的扩展器, 就是处理阈值以上的音频信号但对它进行提升, 也就是上行扩展. 这也是为什么它被称为扩展器的原因. 简单地说, 当音频出现巨大的音量时, 扩展器会将这个音量再次放大, 与压缩器对阈值以上信号压低截然相反. 不过, 还是要记住, 这是默认情况. 记得压缩器里还有上行压缩吗? 即将弱信号提升至阈值附近? 扩展器也有下行扩展, 但也是相反的, 下行扩展器是将弱信号再次削弱. 这其实是扩展器的最常见形式, 因为我们常常用下行扩展器来控制并压低房间噪音, 用以提取更干净的人声. 看到这里你可能会有点眩晕感, 我当初也是. 当然, 也有一种更简单的方式, 非常适用于在有噪音环境下的人声录制, 那就是门限Gate.
Gate 门限
门限是一个信号通过器. 这中间有一个可由用户设定的信号音量点. 当信号音量强度未达到侦测点时, 信号不予通过; 当信号强度到达或超过侦测点时, 信号通过当前门限. 门限的概念跟阈值很像, 某些情况下两者意义相同. 门限很适合用于在零乱散碎的打击乐中, 保持听觉上打击乐的尽可能干净, 也可以用于电台人声与旁白中, 因为它可以在音量极为微弱时直接切断信号, 只有在声音达到一定分贝时才输出信号.
Peak/Trough 峰值/谷值
所有的音频, 都以波形的样子呈现, 既然是波形, 就会有波峰和波谷也就是波浪的峰值和谷值. 我们最常听到峰值Peak一词, 因此数字音频不允许音量峰值超过0db, 这是我们需要时常面对和处理的工作内容.
Clip/Clipper 削波/限幅器
当音频的峰值也就是最大音量超过了数字音频的极限0db, 就会出现削波. 这些超过0db的信号, 就会变成无法识别的数字噪音, 因此Clip削波是个音频界害怕看到的词.
然而Clipper, 限幅器, 意义完全相反, 它并不是产生削波的工具, 而是防止削波的工具, 我觉得将它成为De-Clipper是否更为合适. 总之, Clipper的作用是严格控制音频的最大振幅, 让它无法超越0dB这个终极阈值.
Threshold 阈值
这个就是很多人读成”阀”值的名词, 阈(yu四声)值. 阈值是多个专业领域(不限于音频)都会涉及的名词, 意思是控制点, 当处理对象超过了该控制点, 即开始进行处理.
Ratio 比率
比率这个词如果出现在压缩效果器里, 那么就是指的压缩比. 意即将多少db的振幅压缩到1db. 常见的压缩器里Ratio是个关键选项, 越大的比率, 音频的峰值被压得越小.
Attack/Release 启动/释放
类似于ADSR这个音频包络参数. 但当它俩单独拿出来说的时候, 通常用来指压缩类效果中的参数. Attack和Release通常以时间为单位进行调节, 专指压缩开始和停止工作的速度. 现代压缩器可以完全自定义压缩的起止时间. 但某些复古的压缩如LA2A, 并没有Attack/Release选项, 而如1176压缩, Attack的速度是逐级加快的, 从0.8毫秒(ms)到0.02毫秒, 而Release则从最慢1.1秒, 到最快50毫秒.
Knee 拐点
这是现代压缩效果器里常见的一个参数. 一般来说, 在设定了阈值的具体数值后, 压缩会在音量触发该阈值后进行工作, 音量未达阈值, 压缩就不搭理, 这就说明, 压缩使用的硬拐点模式, Hard Knee. 但如果你将拐点设置为软拐点, 也就是Soft Knee, 相当于你将阈值由一个精确值Point, 拉宽为一个范围值Range. 这样, 当音量还没完全到达阈值数值, 但是进入了范围值时, 压缩会少量的开始工作, 在音量完全到达阈值后全力开始压缩. 也就意味着, 拐点, 将压缩的工作模式由非开即关, 改变为了逐步参与. 在一些带有阈值设定的效果器, 如Gate门限或Expander扩展器中, 也会看到Knee的选项. 在某些复古压缩器如1176机身上, 没有Knee选项, 但随着Ratio压缩比的升高, Knee也会由软变硬.
Gain Reduction 增益减量
增益减量也简称为GR, 这也是常在压缩上看到的名词. 压缩的作用前面说过, 就是对音量峰值进行压缩减小振幅, 这个减去的振幅, 就是增益减量. 所有的压缩器都有GR观察表, 由VU表或Meter电平表表示. 通过观察GR表, 你能快速了解压缩目前的工作状态包括幅度和速度等.
48V(Phantom) 幻象48V供电
很简单, 给电容话筒进行供电的开关. 不过需要了解的是, 某些动圈话筒放大器(动圈话筒的信号比较弱), 也需要通过48V幻象供电进行工作的.
Noise Reduction(De Noise) 降噪
Noise噪音在音频中非常常见, 它会干扰目标声音, 分散听众注意力, 因此需要进行降噪处理. 噪音分为Background Noise环境噪音, Static Noise静电噪音和Noise Floor底噪. 环境噪音会不时出现变动, 静电噪音主要出现在电器连接上, 而底噪则常见在录音设备本身, 当然, 还有类似于风噪, 唇齿声, 意外的碰撞等噪音. 因此在音频后期时, 我们需要使用降噪类的插件对这些噪音进行分析和一定程度上的去除.
Waveform 波形
最常见的音频的数字化呈现方式. 一个单独的声音, 常由ADSR(Attck触发, Decay衰减, Sustain延续, Release释放)四个阶段以一个波浪的形式展现, 故称为波形. 波形以波浪的大小来展示音频的动态.
Spectral 频谱
频谱则是音频的另一种呈现方式. 在从高至低的高频到低频画面中, 音频以不同频率的幅度横向展示. 与波形的区别在于, 波形仅动态展示音频瞬时的音量曲线, 而频谱展示音频瞬时的频率曲线, 因此对于快速发现和处理频率问题来说, 频谱模式更为直观. 你可以简单的理解其为一条动态的EQ曲线.
Tune 音准
音准表示的是声音的音高与整个音乐的音高是否保持一致. 一个年久失修的放置了二十年的钢琴, 和一套管弦乐队合作时, 它肯定就不在调上, 这个不在调上, 就是Not in Tune, 或Out of Tune. 而这些乐器在演奏前的调音, 也就是Tunning. 音准是完全相对的, 只要符合音乐的意图. 比如恐怖片中的怪异弦乐, 就全都不在Tune上的, 但它达到了其作用和效果. 再比如音乐界出名的Auto-Tune, 就是强行将声音偏移到标准音高上, 让声音听起来稳准狠.
Pitch 音高
而在音乐语境中, Pitch则恰恰代表固定音高. Pitch常用音高比如标准音C, 音区比如-1低八度, 升半音#这类记号, 来表达一个准确的音高,#C-1 用以在音乐语境下进行沟通.
Formant 共振峰
共振峰常出现在对人声进行音高或移调处理时. 我们在对人声进行变调处理时, 即使是半个音高的调整, 人声也会出现离谱的怪兽或娃娃音效应, 这是因为人声的共鸣音较其他乐器来说较为集中, 稍微的偏离原始音高, 人声中的大量共鸣音就出现丢失而不会产生新的音高上的共鸣. 所有的音色从人声到乐器, 都有自己专属的较为集中的共鸣频率, 也称为共振峰. 但以人类的最为突出和明显. 这也多半是因为我们作为人类, 对同类的声音有太深的了解吧. 总之, 在对人类调整音高时, 尽可能的反向调整共振峰, 以达到对这种失真的弥补.
Tone/Tonal 音色明暗度
音色明暗度主要出现在染色效果器中, 这类效果器多以模糊的色调处理为主, 而使用Tone/Tonal来偏重处理音频的高低频率. 这种明暗度有时候也会使用Color一词来形容, 如Bright或Dark来表示整体声音的明亮或阴暗.
Frequency 频率
频率是构成声音的主要元素. 频率的震荡由慢到快形成低频到高频. 人声最多能听到从低频20Hz到高频20KHz以内的频率, 我们也常常看到音响产品的说明书里, 会有一个关于产品的频率曲线以示意产品的声学上的特点. 也因此大部分Equalizer(频率均衡器, 简称EQ)会有一个20Hz~20KHz的工作区域, 帮助我们观察频率并通过修改曲线, 来改变频率的呈现以实现目标.
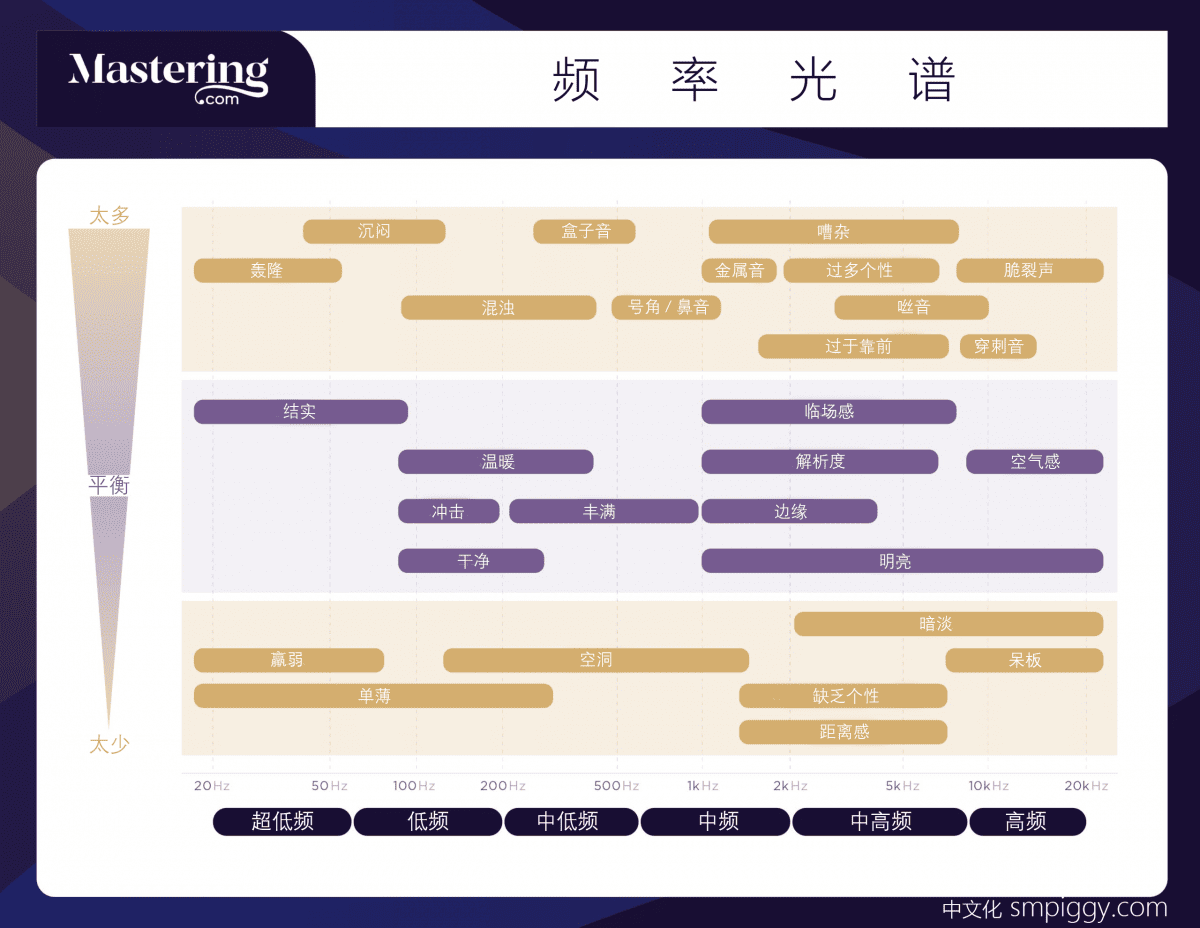
频率在音乐与音频, 乃至于声音中都是最重要的元素. 任何声音在发出时就伴随着它独有的频率, 而这些频率可用来帮助我们对声音进行识别. 但音频应用中, 我们经常需要将多个声音混合在一起, 这就会导致频率上的冲突. 如何保留声音的性格, 但又要在多个声音中做出割舍和避让, 就是一门学问了. 上图是来源于Mastering.com官网的一张频率个性图, 我做了中文本土化以更方便参阅. 这张图从纵向的响度, 与横向的频率分布, 进行了一个较简单却有效的形象化概括, 非常值得在处理音频频率时进行参考.
Frequency Response 频率响应
频率响应主要指理想中的频率曲线, 在现实设备中的体现.
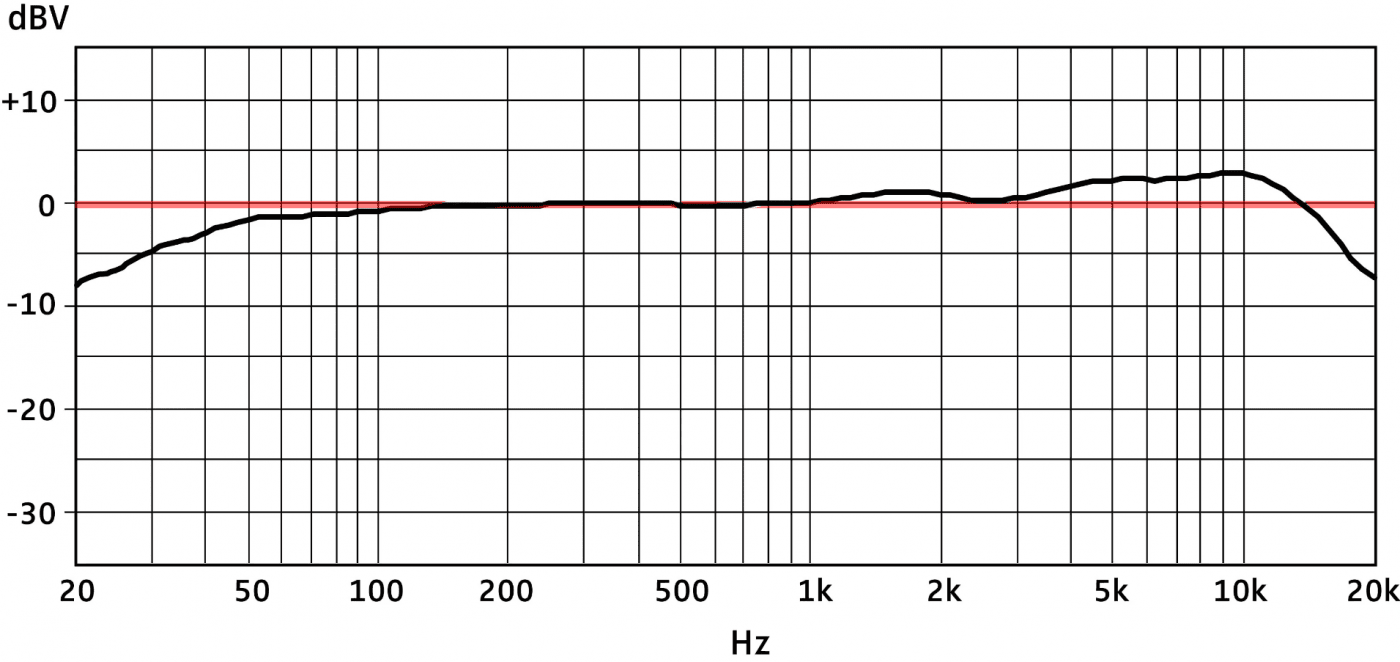
我们常以一条频率从20Hz~20kHz的电平为0dB的平直直线, 作为参考线, 而任何设备在这个频率范围内不同频点上所能捕捉到或回放出的信号强度, 就是该设备的频响曲线. 现实世界中, 没有完美的频响曲线, 不同的录音设备也因其独特的频响曲线, 而成为其受人追捧的优点, 或避之不及的缺点. 不过, 在混音及母带过程中, 监听设备则必须达到频响曲线的尽可能平直.
EQ/Equalizer 均衡器
均衡器主要用来修饰频率. 均衡器包含几个关键参数, Freq(Frequency的简写, 频率或频点), Gain(增益), Q值(幅度), LC(Low Cut低切, 也可称为HPF, High Pass Filter高通滤波)和HC(High Cut高切, 也可称为Low Pass Filter低通滤波)
Esse/Sibilance 齿音/嘶音/咝音
不同的话筒, 不同的空间, 和不同的录制方式, 在拾取声音时, 都会不同程度的导致音频在高频上产生共鸣, 有些共鸣很悦耳, 但如果这些共鸣出现在4~8KHz的范围内并特别突出, 会造成音频尖锐割裂的感觉. 尤其在人声发出”S, C, SH, CH”等辅音时, 或者一些弦乐在错误的环境下使用错误的录音设备, 也会造成高频的不悦感, 这些都称为齿音或嘶音Esser或Sibilance. 这些都需要在后期进行一定程度的压制或消除, 以提高可听性. 因此, 需要在EQ均衡器中对4~8KHz的频率进行寻找和试听, 再尝试消减. 也有很多专用的插件有去除齿音的功能, 一般名为De-Esser, 这类插件使用动态EQ的方式, 不停的压制4~8KHz(或手动设定频率)的声音从而压低齿音.
Slope 斜率
Slope, 斜率, 这个词经常出现在Filter滤波中, 滤波也是EQ中处理方式的一种, 通常分为低通滤波Lo-Pass或高通滤波Hi-Pass, 也就是切除高频, 让低频通过, 或, 切除低频, 让高频通过(因此也会被称为高切Hi-Cut和低切Lo-Cut). 但这个切除的斜率, 会决定频率之后的呈现. 缓和的斜率, 会让频率以较为舒缓的形式逐渐被切除, 而陡峭的斜率会干净利落的切除不需要的频率. 而斜率的斜度由具体的数值来决定, 比如每个八度衰减6dB, 到每个八度衰减96dB, 甚至到垂直切除这就是斜率 – Slope的作用.
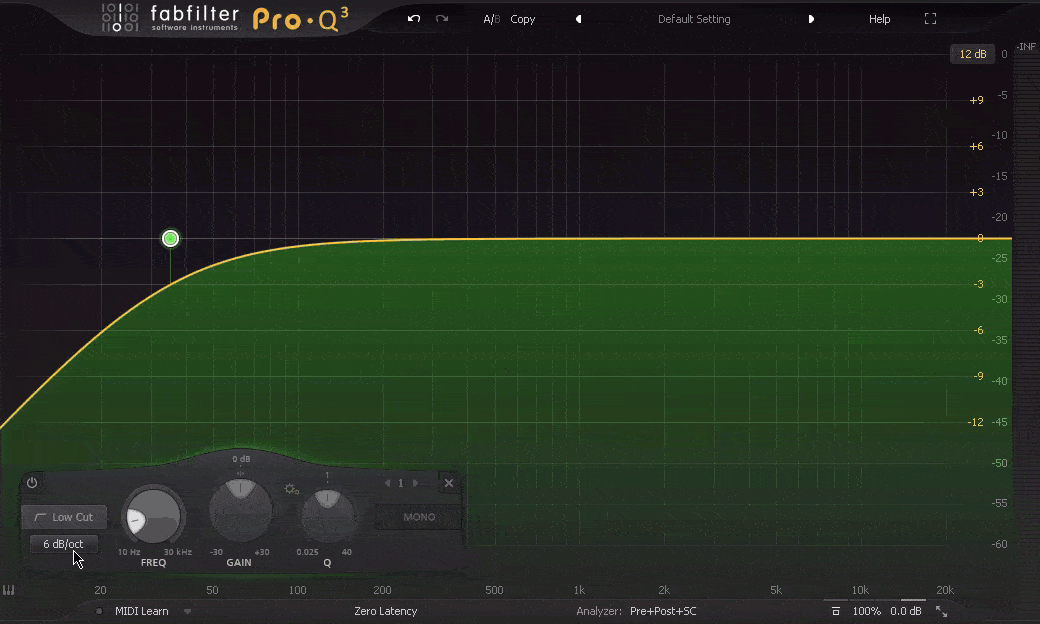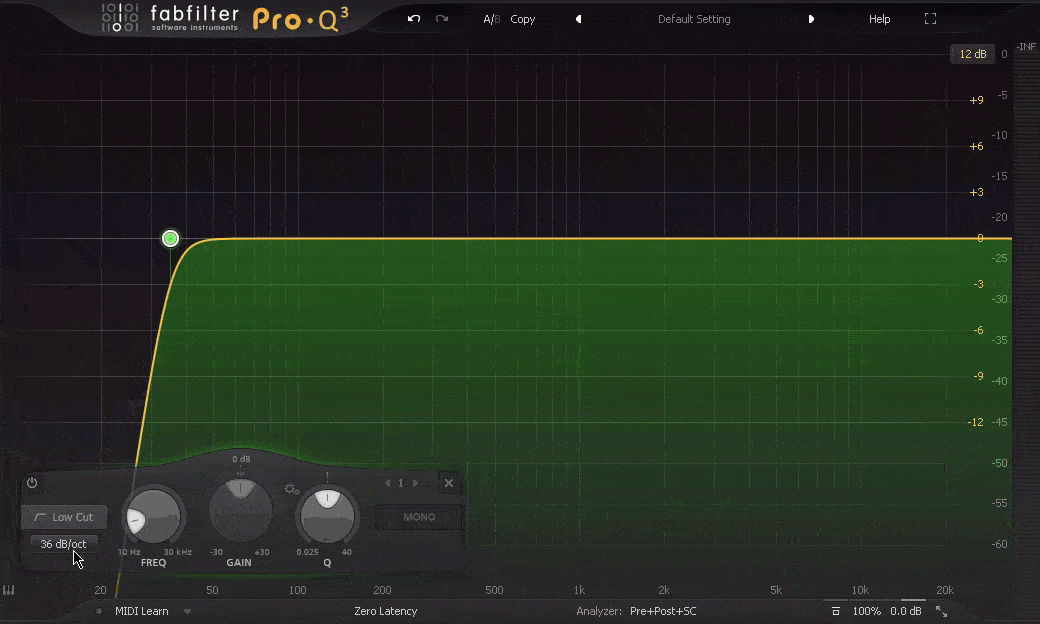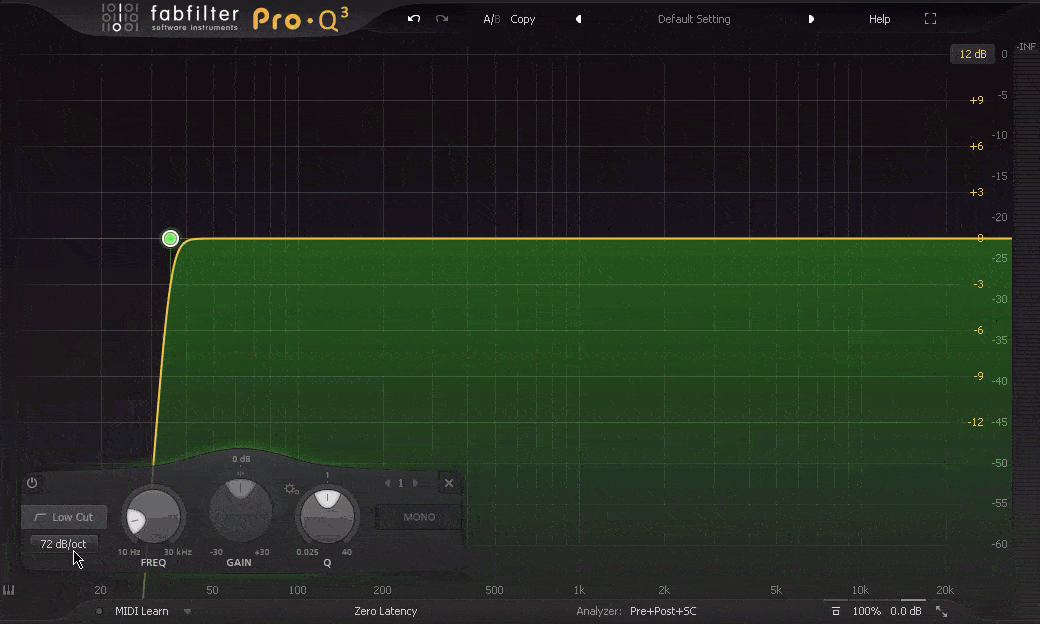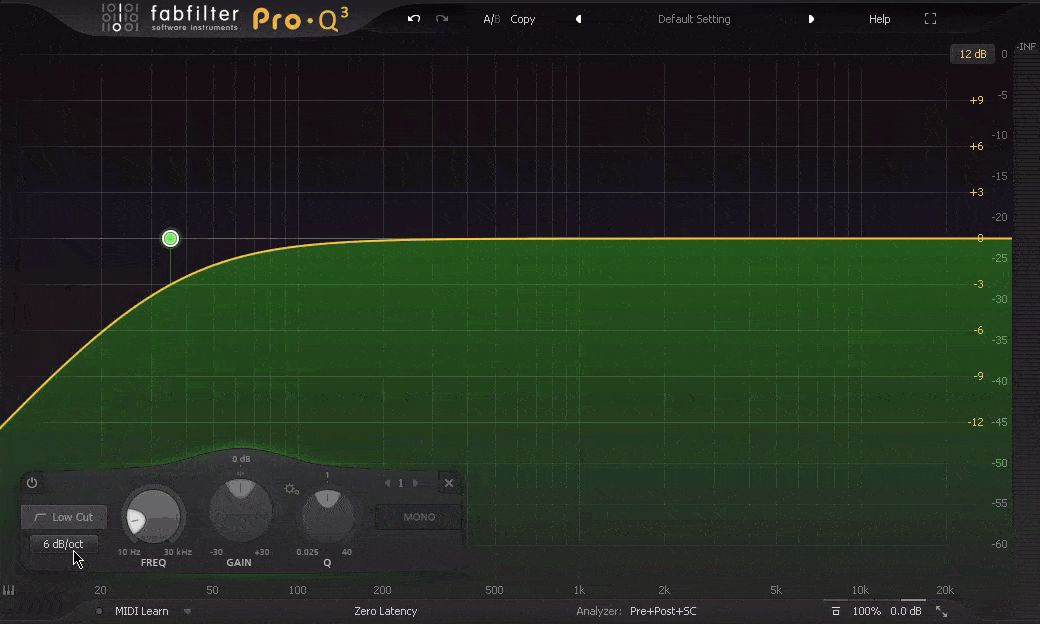
Filter 滤波器/频点
滤波器执行一个任务, 就是将某一个指定的频率进行进行内容上的提升压低或是切除. 所以滤波器在EQ中也称之为频点, 围绕这个点我们对频率进行特殊加工. 在EQ中, 我们可以对频点进行几种外型定义, 如Bell钟型频点, 意味着它外形像钟或铃铛左右对称, 围绕频点做圆润的上升和下降. Shelf搁架型频点, 意味着它像一块搁板一样可对频点做抬高或降低, 且在它之后的频率将保持这一状态. Band Pass带通, 意味着在一个较宽的频率范围内, 频点都保持在水平高度. Notch凸点则相反, 频点形成一个极其锐利的尖刃能干净的去处较窄范围内的频率(Notch通常用来切除, 因为用来提升的话听感会非常糟糕).
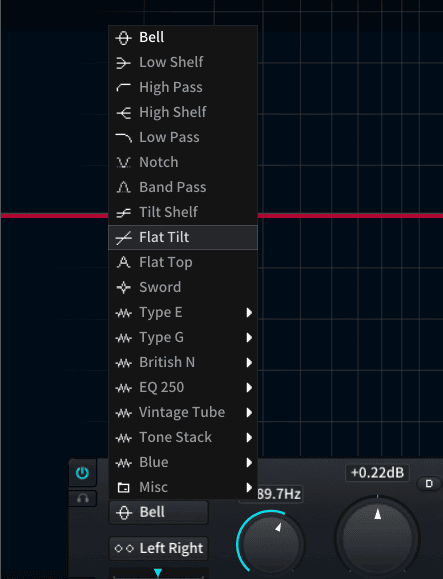
Steep 陡峭
Steep通常用来形容曲线的陡峭犀利。与之相反的就是平缓 – Gradual/Gentle/Moderate
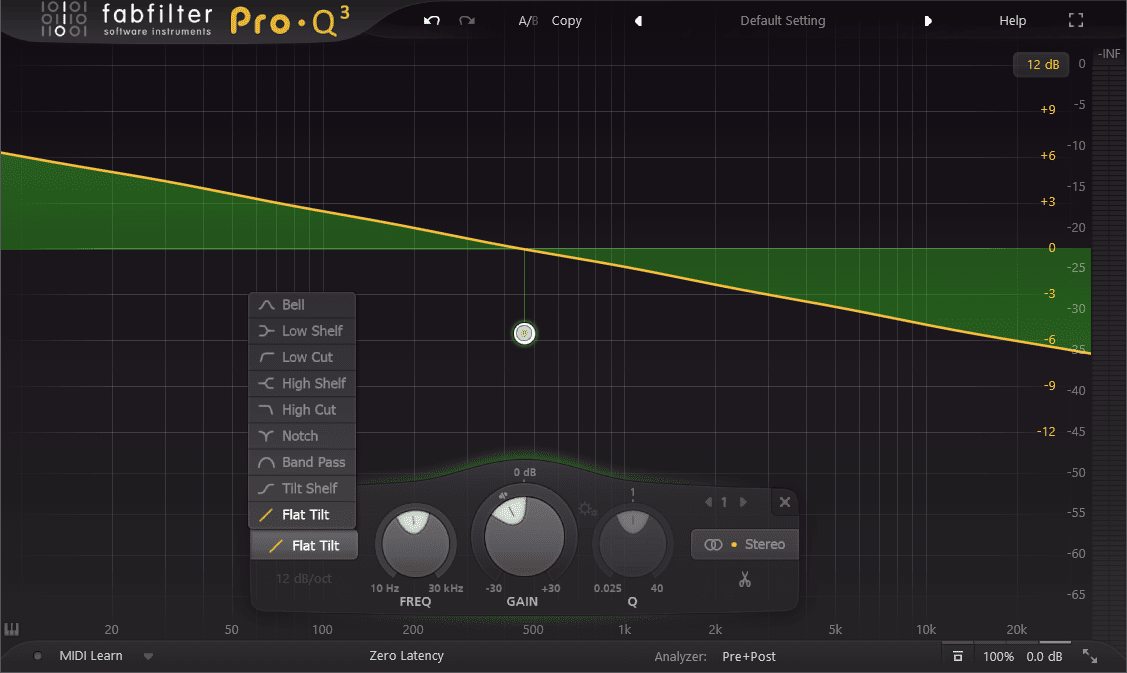
Tilt 偏转
偏转一般以一个频点为中心, 进行顺时针或逆时针的偏转, 从而调整该频点两侧的高低频率. Tilt有两种模式, Flat Tilt和Tilt Shelf. Flat Tilt平直偏转会形成如下图一样的线性过渡, 而Tilt Shelf, 则会围绕频点同时形成两个相反的搁架式滤波.

混音类常用术语
EQ Match 频率匹配
频率匹配是将某个声音的主要频率进行捕捉, 再套用到另一个声音上的方法. 比如在混音中, 我们临时要用一把新的贝斯来替换原来工程中的贝斯音轨, 由于新贝斯的声音频率不太相同, 这可能会带来复杂的重新混音的过程, 我们就可以利用EQ Match来捕捉原始贝斯的主要频率, 再套用到新贝斯上, 来迅速达到既更换了音色, 又不至于全局推翻的混音结果.
Sub 次低音(超低音)
次低音是指低于70Hz的频率, 这类频率越低, 可听见性也越低, 但依然可以被人体所感受. 次低音和低音都会增强声音的力度, 但由于能量巨大, 过量的次低音会导致音频混浊, 也会大量占用响度空间. 因此如何控制次低音来平衡声音的响度与力度, 是混音中需要着力的部分.
Gain Match 增益匹配
混音过程中, 会遇到比编曲与录音更多的效果处理, 一个音轨可能会经过EQ, 压缩, 再EQ, 再压缩等复杂的效果链. 而这效果链的每一个环节, 都可能会改变音频的响度, 如果不及时调整, 一环一环的下来, 音频本身的特色可能无形中消失殆尽. 因此我们需要在每一个环节, 也就是每一个效果器上, 确保音频从进入到流出都尽可能的符合健康, 也就是尽力达到信号进入的响度和流出的响度基本一致. 这个处理过程就叫做Gain Match增益匹配.
Headroom 余量(头部空间)
所有数字音频都受到一个问题的困扰, 就是音频的音量是无法超过0db的, 一旦超过0db音频就会失真, 如同照片过曝. Headroom就是音频当前峰值与0dB之间的余量. 在混音中, 多轨音频的音量会累积, 因此总音量的Headroom会快速减少甚至瞬间超越0dB从而造成失真. 但由于我们不断希望音频达到足够的响度, 意味着音乐的总音量又应该无限接近0dB. 因此, 如何调整每轨的Headroom, 同时如何令总输出音量无限接近0db, 成为了技术话题. 使用EQ去除音频中无意义的频率, 或是使用压缩对极度不稳定的音量起伏进行控制, 都是榨取剩余余量的手段之一.
Loudness 响度
响度, 就是在不超过0db的前提下, 音频的综合听觉音量. 听起来很简单对不, 输出推到最大, 然后加个0db的Limiter限制器不就行了? 不, 电平表上的音量和听感上的响度其实完全不同. 以前在刚刚由模拟转入数字时代时, 我们对音频的测量, 全部以音量为标准, 且普通认为, 保持音量饱满, 且Peak(峰值电平)不超过0db就够了, 这导致了一种局面, 人们会不断的利用压缩及多种混音手段, 将音频音量堆到接近0dB的极限, 并以为这就会达成充满竞争力的听觉效果. 但事实是, 这种手段降低了音频的动态, 也降低了音频的听感. 好在, 现在出现了新的测量标准, 响度Loudness, 并以LUFS为测量值, 它不再以瞬间的音量为评判标准, 而是以音频的完整播放为测量周期, 结合感知响度(Perceive Loudness)来评判, 并给出不同音乐类别的建议响度值, 这种更科学, 更符合人类听感的测量方式, 成为了现在更主流的响度标准.
和以前那样, 不断将音量推在顶峰的做法, 尽管不会出现失真, 但在现在的响度评判中, 可能会成为糟糕的响度, 甚至可能会被上传的网络平台做出响度惩罚, Loudness Penalty, 即平台会直接降低你作品的音量, 因为它太过吵闹. 如果想测量自己作品的响度, 可以寻找Waves的WLM, iZotope的Insight之类的插件, 进行测量. 而一般来说, 值越大, 响度越大, 但也越危险. LUFS值在-6~-9左右, 过于响亮, 且一定会被平台惩罚, LUFS值控制在-10~-14左右的, 都是安全的响度值.
Latency 延迟
这个延迟, 不同于Delay延时. 那延迟是什么意思呢? 延迟是指, 在音频系统中, 从你下达播放声音的指令, 到声音事实上被播放出来, 中间的差值. 这个差值取决于你的系统配置, 音频接口, DAW的设置, 及加载的效果器对性能的要求等的总和.
延迟首先就会来自于采样精度. 即使专业音频工作室中都使用高精度的音频接口, 比如支持192KHz每秒等. 但这些高精度的音频信号依然需要高强度的CPU和数据传输能力, 将它们传递到电脑中并记录下来. 越高的采样精度, 就越会出现翻倍的数据量, 这些会大大超过CPU工作能力, 就需要通过延迟来分配CPU的运算, 降低峰值强度, 来达到性能上的平衡.
延迟还来自于效果器. 我们已经知道, 数字音频中非常依赖CPU, 来协调音频接口到DAW中间的数据传输, 而添加的效果器同样需要CPU进行即时的信号处理, 当我们在音轨上不断叠加效果器时, CPU就要依次运算出第一个效果器的音频, 第二个, 第三个, 以此类推, 最后呈现出处理后的最终声音. 如果我们对CPU非常残酷, 要求它在0秒内完成这些运算然后将声音传递出来, 一来不符合事物发展规律(运算和数据传递就会需要时间), 二来CPU很快就会满载然后烧掉. 因此我们依然要通过添加延迟来缓解CPU的峰值压力.
不过不用担心, 大部分延迟都由系统替你决定, 甚至你根本没有插手的机会.
由于延迟会延后声音完成的时间, 我们在录音时, 会尽量使用最少最少的效果器, 意图将延迟控制在极低的水平. 我们知道, 歌手在录歌时, 是需要听到耳机中的伴奏和自己的声音的, 这个声音最好能达到0延迟, 这样歌手每一次开口, 每一个收尾, 都能在自己的控制之下. 如果延迟较为明显, 歌手唱出的声音要1秒后才能出现在耳机中, 那显然连节拍都对不上.
而在混音中, 我们对待延迟是较为宽容的. 混音中, 我们会需要调用大量的效果器(录音中也需要, 但混音显然需求量会多得多). 每当我们添加更多效果器后, 整个DAW的延迟量就会变得更高. 这时候我们必须做出妥协, 让渡出一点缓存空间, 让CPU正常且安全的处理数据. 因此, 我们在叠加效果器后, 常常会发现DAW里的延迟, 会从0.0ms, 逐渐升到23ms, 85ms等等等等. 但哪怕延迟上升到了几百毫秒, 对某些混音师也是可以接受的, 因为混音过程不需要录制, 输入到输出的时间差不在我们的考虑范畴. 我们只听输出和音质.
某些超采样效果器, 在开启超采样或者几倍率的超采样后, 延迟会指数级攀升, 也同样是这个道理. 超采样也是处理精度的一类, 它需要CPU进行更猛烈的运算来得出非常精确的音频, 可以预见的会大大提高延迟.
Oversampling 超采样
在效果器对音频的处理中, 常常由于对数字音频的模拟化处理而出现噪音, 从而影响信号的纯净度. 为了抑制这一噪音, 效果器通常会内置一个隐形滤波器进行噪音过滤. 然而这个滤波过程在原始采样精度下会略微的溢出截止滤波范围, 导致原始音频被破坏. 为了提高滤波精度能更准确的过滤指定范围内的噪音(不溢出截止滤波范围), 就需要效果器临时将处理精度提高至原始采样精度的两倍或以上, 来保护音频的完整性和纯净度.如果原始音频采样率为44.1KHz, 超采样2X就是88.2KHz, 4X就是176.4KHz. 超采样虽然会提升音频的精度, 但也会大幅提高系统资源的占用.
这里有一篇非常通俗易懂的文章, 解释了Oversampling的原理和用途. What is oversampling in audio? 可以通过Google翻译为中文更适合阅读.
Look Ahead 前瞻
前瞻. 混音中, 我们在使用某些效果器时, 会发现效果器上有个Look Ahead按钮, 也可能是选项. 当我们激活它时, DAW的延迟量变高, 也就是说我们的声音会多一点延迟再传出来. 这个look ahead的意义何在呢? 其实, 所有的效果器尤其是压缩类效果器, 在第一个声音出现时是否能及时参与工作, 很重要. 这就好比流水线上的包装机, 如果等产品上线了再开始运行, 往往会错过第一个产品的包装, 产品倒是好说, 工人抓起它再塞到流水线后面插个队就行了. 声音一旦出炉, 错过就错过了. 很多复杂的混音中, 一序列的效果器在逐步运行中将声音糅合在一起, 如果错过第一个音, 会显得无比突兀. 为了达到完美的效果, 很多效果器会附带Look Ahead选项, 即创造一点延迟, 让音频先进入这个效果器进行运算后再传出来到你的耳朵, 而后你听到的第一个音, 其实就是已经进行过效果处理的好声音了. Look Ahead和Oversampling一样, 都是为了实现完美的声音处理, 而做出的处理时间上的牺牲.
Low/Mid/High 低中高频
Cut/Pass 频率切除/通过
Parallel Compression(New York Compression) 平行压缩(纽约压缩)
平行压缩是一种独特的压缩方法. 常见的压缩方式, 是直接将压缩插入音频并直接得到压缩结果. 而平行压缩是将音频进行复制, 将原始音频与复制音频同时发送, 原始音频直出, 而复制音频经过压缩器, 然后再将两个音频混合, 得出一种原始与压缩后两个信号的重叠信号. 这种方法, 可以将一些压缩效果过于猛烈但又极富特点的压缩信号, 轻微的叠加在原始信号中, 得到一个较柔和和新颖的听觉感受. 现代的软件压缩器多已附带了Mix旋钮, 用来直接控制原始信号/压缩信号的混合比例(干湿比).
Dynamic EQ 动态均衡
动态均衡是均衡器的增强型, 动态均衡除了执行常规的均衡操作外, 还可以根据信号的动态幅度, 对指定的频点或频段进行增益和衰减的限幅设定. 动态均衡就像是传统均衡与多段压缩的综合体. 动态均衡和多段压缩的最大区别在于, 动态均衡的可设定频点更多, 但没有更深度的压缩设定选项. 多段压缩的频段较少, 但每个频段都拥有完整的压缩功能. 总之, 动态均衡着重点在于精细调整均衡, 而多段压缩着重点在于控制各频段响度, 两者各有不同, 但也确实存在大量重复的功能.
Dynamic Resonance Suppressor 动态共鸣抑制
一种新兴的动态EQ, 它结合了动态EQ与多段压缩的特点, 可实时监测音频信号中超出平直范围的共鸣频率, 并加以抑制. Soothe开创了这类产品的先河, 它对人声中的齿音, 弦乐中锐利的丝弦音, 吉他中强烈的擦弦音, 或是鼓组中混浊的中低频音都能起到明显的改善作用, 也是现代混音中不可或缺的利器.
你可能会疑惑, 动态共鸣抑制, 和动态EQ有啥区别呢? 动态EQ通过添加非常多的动态频点, 确实也可以对这些共鸣频率进行动态抑制, 问题是, EQ中的频点是固定, 不会移动, 当音频中音高出现变化时, 这些共鸣频点也全部会出现偏移, 你之前设定的这些频点就全部无效了. 动态共鸣抑制则基于每一次出现的基频推算出上方的共鸣进行动态抑制, 也就是说它的频点是自动捕捉, 而非固定的. 这样应该就更好理解两者的区别了吧.
Multiband Compressor 多段压缩
多段压缩是压缩器的进化变种. 常规的压缩器, 是根据输入的信号音量和人为设定的压缩值来决定后续的压缩行为, 但这对于日益复杂的音频信号处理, 略显功能单一. 比如在母带处理阶段, 单一频段处理的压缩, 很难应对各式各样来源的混音作品. 有的作品低频缺乏弹性但高频表现不错, 有些则反之. 仅用单一频段处理的压缩器, 无论怎么处理都无法各频段的稳定. 因此, 多段压缩诞生了. 多段压缩, 会将这个输入信号, 根据人为设定的频率分割为多个频段”Band”, 发送给多个压缩区块. 压缩区块根据这些频段的不同音量来进行独立的压缩, 最后在效果器的尾端将这些压缩过的分割频段进行融合并输出. 这样就可以对不稳定的频率进行加固, 而对表现出色的频率进行忽略, 从而将整个信号质量进一步提升. 多段压缩不仅可用于母带处理, 一些频段较宽动态较大的乐器声部也可以单独使用, 如钢琴, 吉他, 人声, 弦乐等.
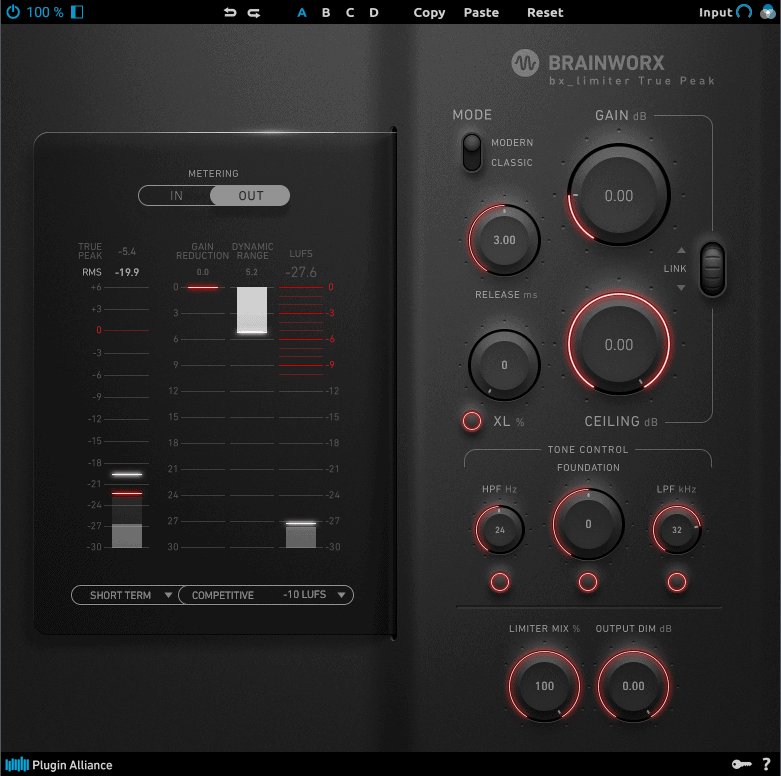
Limiter(Limiting) 限制器
限制器就是非常严格的压缩器, 也成为砖墙压缩. 在数字音频领域, 有一个终极戒律, 就是音频响度不得超过0dB. 在压缩器中, 音频超过阈值, 压缩器就会启动, 并按照设定的比例来压低音量, 但由于是按照比例, 那么巨大的声音即使被压缩压低了音量, 也依然会保持较大的动态, 而这些动态依然可能冲破0dB的数字音频限制, 导致声音失真和削波. 而在限制器中, 会多出一个Ceiling的参数, 用来极限切除一切可能超过Ceiling参数的信号. 也就是无论多大的音频信号, 即使超过了阈值, 也无法超过Ceiling, 这就保证了最终音频严格的处于Ceiling设定的响度以内, 从而避免冲过0dB的数字戒律. 除了极限的压缩, 限制器还附带增益控制, 可以先将音频提升到一定响度, 然后再极限压制它的峰值, 从而得到响度的提升. Limiter是音乐制作完成最终即将面世的最后一步.
Ceiling 吊顶
前面说过, Ceiling一般出现在限制器中. 在限制器中, Threshold用来处理主要的响度压缩, 而Ceiling则执行限制器的作用.
我们知道数字音频的极限是0dBFS, 而大部分数字音频出品, 我们并不敢将最终峰值控制在0dBFS, 这是因为, 在数字音频为了应对网络传播而进行压缩输出时, 会降低采样精度. 而采样精度在降低时, 其边缘解析度会失去精度而产生边缘失真. 这些失真就会导致数字音频的最终峰值, 实际上会不时低于或超过了当前显示的数值. 这就意味着我们需要在最终压缩阶段, 对音频进行一个低于0dBFS的峰值限制, 这个峰值限制, 就是Ceiling. 通常, 我们可以将Ceiling设置在-0.1dBFS~-1dBFS之间. 如果你的数字音频一直以无损音质(如wav, aiff等格式)传播, 那么Ceiling设在-0.1dBFS都是安全的, 如果你的数字音频可能会遭遇大幅度的低质压缩, 那么进一步降低Ceiling到-0.3dBFS~-1dBFS可预防未来可能出现的失真.
我甚至为了测试这一点专门进行了试验. 我选择了一段音频片段, 使用Limiter将它限幅在-3dBFS, 然后将这段音频输出为24bit, 44.1kHz的wav和320kbps, 44.1kHz的mp3, 然后再将两个文件导回到项目中, 分别播放它们, 结果是, wav文件严格维持了之前输出所设定的-3dBFS的峰值, 而mp3文件, 峰值一度到了-2.98dBFS, 其余部分回到了-3dBFS. 如果我的limiter设置为0dBFS的峰值, 那么这段mp3在某个瞬间, 超出了0.02dB, 就造成了失真(即使这么短的时间人耳几乎来不及听出失真, 但作为专业输出, 这个音频是失败的). 结合我多年的经验, 无论是无损音频在转换为压缩音频, 或将压缩音频转换为无损音频的过程中, 这种采样精度的改变, 都会造成ISP(Inter Sample Peak), 也就是采样间隔峰值, 它位于两个采样点之间, 因此不会被传统的效果器捕捉到, 也无法判断其准确峰值, 但它是波形的, 事实上会或高或低于两个采样点的峰值, 如果这是一条母带音频, 且峰值被设定为0dBFS, 那么在转换为压缩文件中, 它一定会出现超过0dB的波动, 最终毁掉这条音频.
关于Peak和ISP, 后面的词条中也会提到.
Monitor 监听音箱
Monitor在电脑语境中,一般指显示器。然而在音频环境中,它用来表示监听音箱。因此,我们经常看到国外的术语中,称呼工作室音箱为Studio Monitor,而不是Speaker(Speaker也会出现,但更常用来表达民用级别音箱)。
Headphone/HP 头戴式耳机
在混音的监听耳机中,头戴式耳机也分为封闭式Close back,和开放式Open back。
Sub Woofer 低音炮
大部分工作室监听音箱,由于体积原因,无法达到较低的低频下潜,这就会导致在小型音箱上进行的混音,由于无法判断低频强度,而导致混音作品在现场播放时会出现低频的混乱(低频过多或不足),因此一般工作室都会为低频的监听专门添置低音炮,来获取低频部分的监听。
Listen Bus 监听总线
在混音中, 我们可能会用到完全不同的耳机和音箱. 这些设备由于机体不同, 对频率的响应也是千差万别. 这也就导致我们不能准确的混音出接近标准的音响内容. 因此我们需要在总输出上添加校准软件, 比如对监听耳机中偏多的低频, 进行反向的压制, 欠缺的高频进行反向的补偿等等. 但这样也会导致总输出上的压限器对于响度的判断出现误差, 而且在输出时我们还需要关闭校准软件, 这些都增加了巨大的繁琐与不确定性.
很多DAW都在总输出旁加入了一个信号回路, 让总输出的信号在尾端额外复制了一条称为Listen Bus的总线, 我们可以在这条总线上加入校准软件, 从而监听到更准确的频响, 同时由于该总线是主输出的复制体, 只输出而不输入, 因而不会影响到主输出上的各种效果器及压限器的判断, 且输出时该监听总线也不会加入合成中. 这对混音无疑是巨大的帮助.
Trim 校准
在一部分音频设备或插件上, 我们可能会看到Trim的旋钮. 它会改变音频的音量. 但你一定不要把它和Gain混为一谈. 如果你还记得Gain增益的定义, 那就应该记得, 增益是通过加大电流, 来增强信号强度, 增益会改变信号的音色. 而Trim则不是, Trim一般在设备或插件信号链的末端, 用来对信号(或增益过的信号)进行音量上的微调. 而这个音量上的微调, 不会强化或弱化声音的任何特性, 只是单纯的降低音量电平.
你也可以将Trim看成你的DAW中的轨道推子Channel Fader, 两者功效一样, 只不过一个出现在设备和插件界面中, 一个出现在DAW中.
当然, 我们也会在音频文件剪辑中看到Trim, 它在这种环境下代表修剪和对齐, 用来精确剪切音频段落的起止.
True Peak TP/真实峰值
真实峰值一般出现在现代的数字限制器中, 且现在流行的大部分数字限制器, 也都是真实峰值限制器.
真实峰值是什么意思呢? 在传统数字限制器中, 限制器与项目保持一致的采样率, 或无法获得更高的采样率, 因此会造成, 这些限制器无法侦测到两个采样之间的峰值(也称为采样间峰值, Inter-Sample Peaks, ISP).
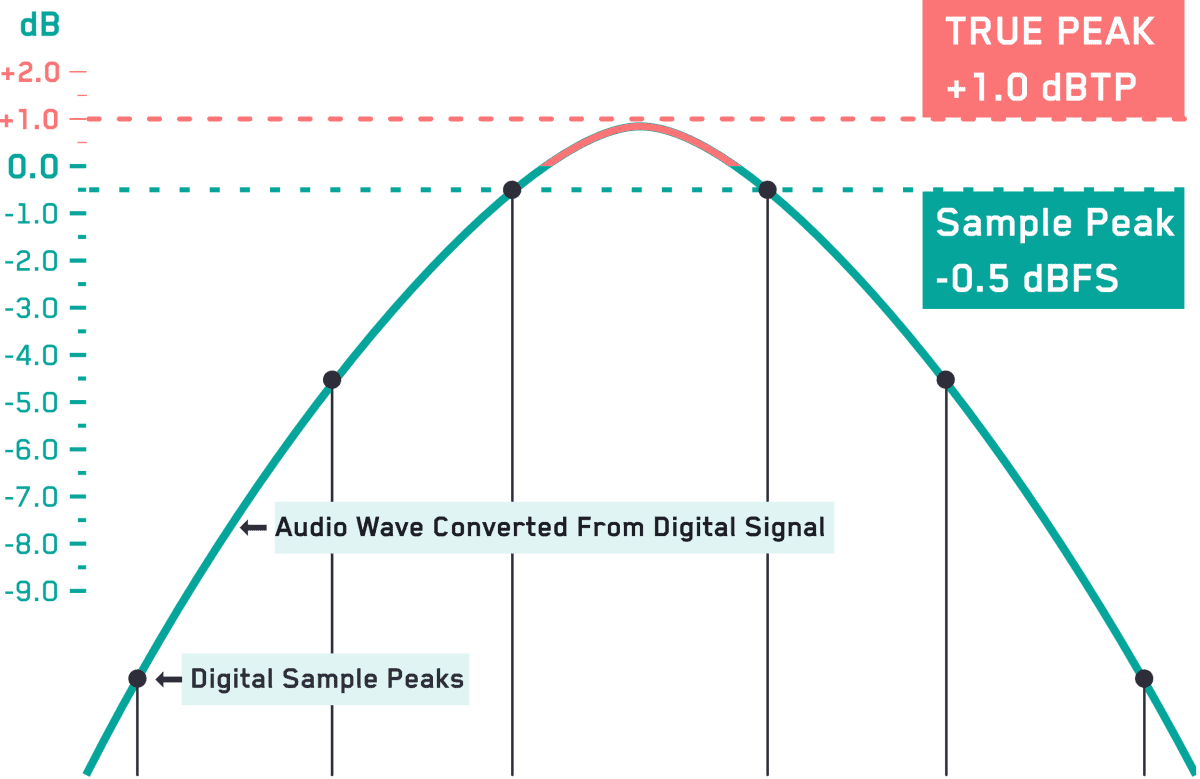
如上图所示, 由于采样率的限制, 两个采样间的音频峰值, 极有可能超过0dB且无法被检测到. 你看到的电平表上显示峰值为-0.5dBFS, 安全着呢, 其实瞬间峰值可能已经达到了1.0dBTP, 爆表了都.
常规的限制器, 只能按照你的项目设定的采样率, 来间隔性检测采样点的峰值, 这就意味着它们只能根据两个采样的前后值来做出压限动作并给出读数, 而漏掉中间的峰值. 这样不但读数可能不具备参考性, 甚至连输出信号都可能造成超越0dB的终极失误.
而真实峰值限制器, 就考虑到了这种情况, 它们一般会从两个方向来预防ISP的峰值超越问题. 一是Oversampling, 前面说过的超采样, 这类限制器会以项目设定的采样率翻以数倍, 来增加读取采样的密集度, 减小漏过间隔采样的几率. 二是Look Ahead前瞻, 让信号提前进入限制器对信号的增减幅进行预判, 来估算出采样间隔峰值的数值. 现在市面上流行的真实峰值限制器, 应该已经能够完全处理ISP采样间峰值的问题了.
但这只是理论上的. 前面列举了真实峰值限制器的两种工作方式, 注意到没有, 一种是减少错判几率, 一种是预判峰值走势. 没有一种能给出准确的答案的. 事实上, 如果你的项目设定采样率, 和你最终输出的文件采样率一致的话, 两种真实峰值限制器的估值误差都接近零, 也就是相当完美. 但一旦涉及到你的输出码率和采样率有所变动, 比如输出为有损压缩文件时, 真实峰值限制器的努力依然会白费一半. 我测得的大多数无损转有损, 都会出现0.01dB的峰值差值. 所以, 这又回到了我们说的限制器中的Ceiling的重要性, 不要让它真的处于0dB位置, 而是适度减少.
Mid/Side 中置/旁侧
我们在日常混音时, 通常使用的是单声道和立体声模式. 这对于常规混音来说已经足够. 但Mid/Side中侧模式的出现, 让声音有了新的空间感.
Mid/Side模式分为M/S录音模式与M/S处理模式: M/S录音会使用一个单声道话筒录制正前方的声音, 一对立体声话筒录制两侧的声音, 在后期混音时, 调节正前方和立体声声音的比例, 可以营造出近大远小或类似于单反相机前景后景层次感的效果. 由于这个独特的声场感, 很多效果器也在处理模式中加入了M/S处理模式, 它会在内部将你普通的立体声信号转换为中间声道和两侧声道, 再应用不同的处理级别, 然后在输出端还原成立体声. 这意味着, 哪怕是一段已经合成好了的歌曲, 你也可以用带M/S模式的效果器, 将中间的人声再一次提亮或压缩, 而尽可能的维持旁侧音乐的原状.
Side-Chain(Ducking) 侧链
侧链指的是, 通过其他音频的振幅来影响本音频的一些行为. 比如, 本音频加入了一个压缩, 在这个压缩的侧链上再引入另一个音频, 那么另一个音频的振幅就会取代压缩原本的设定, 从而改变本音频的压缩幅度. 理解侧链最简单的方式是, 在一个以长音为主的贝斯音轨上, 为贝斯插入一个带侧链功能的压缩器, 然后在这个压缩上通过侧链引入一个较为活跃的鼓片段, 接着观察压缩器被鼓片段影响的参数变化, 同时聆听贝斯音轨被压缩改变的声音, 这就是侧链的核心功能.
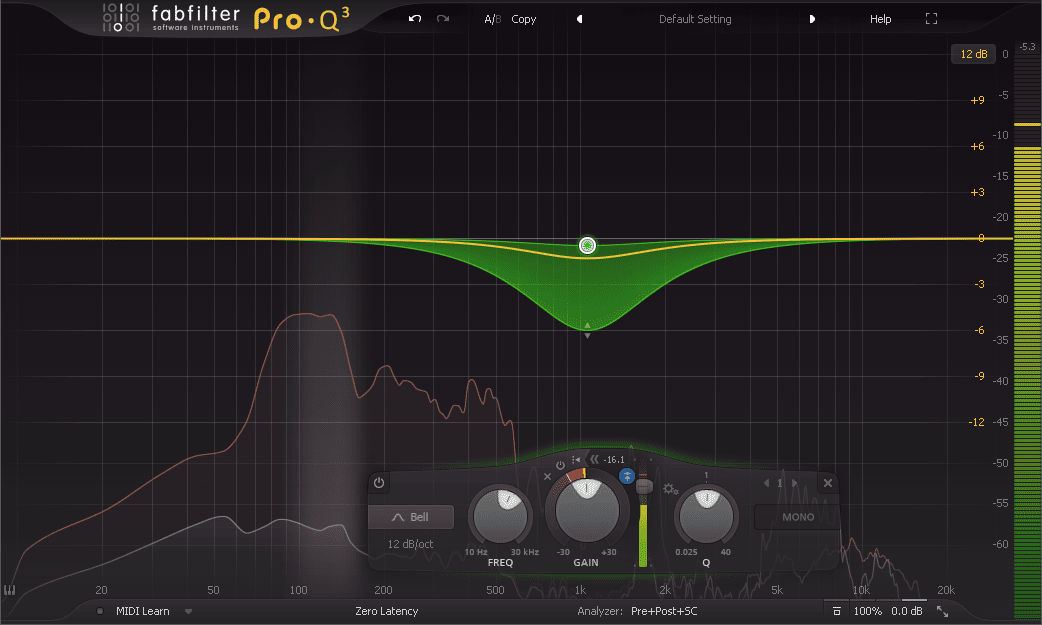
侧链不仅仅可以用在以信号响度为来源的压缩领域, 还可以用在以信号频率为来源的动态均衡领域. 虽然两者都是动态处理, 但以信号频率为来源, 用以干涉当前音频的频率, 也是非常有创意的用法. 比如在播客中, 人声与背景乐同时播放. 背景乐使用压缩, 以人声为来源作为压缩的侧链, 以达到人声出现时, 背景音乐被压缩的目的. 但同时, 我们还可以在背景乐中加入动态EQ, 同样以人声为来源做侧链, 当人声的主要频率出现时, 背景乐的相似频率被抑制, 以避免出现频率混浊或干扰人声.
Automation 自动化
自动化并不是行业里的高科技, 它其实只是一个记录实时参数变化并在回放时可不断重播的简单技术. 现在的DAW中基本都支持参数Automation自动化. Automation一般可用在MIDI CC参数, 音量, 声像, 效果器参数等一切可变变量中, 且包含Read, Write, Latch, Touch, Off几个选项, 当我们找到Auto这个开关并切换到Write, 并开始走带(播放), 就可以随意的用鼠标控制当前界面的任何参数并看到写入参数变化了(自动化会自动为修改的参数新建一条控制曲线). 当我们停止走带, 并将Write切换到Read, 然后重新走带时, 这些调整过的参数便开始按照勾画的曲线自动回放, 这就是自动化. 自动化里的Latch, 意思是一旦出现最新的数据, 这个数据将一贯到底并覆盖之前的数据, 而Touch则是, 只有在保持控制状态下写入新的数据, 松开控制便停止写入并回到上次的数据中. 自动化无论在编曲还是混音中都非常重要, 比如我们可以通过混响效果器的音量自动化, 在某一段钢琴中逐步加入混响, 而在这段结束后逐步关掉混响.
Phase 相位
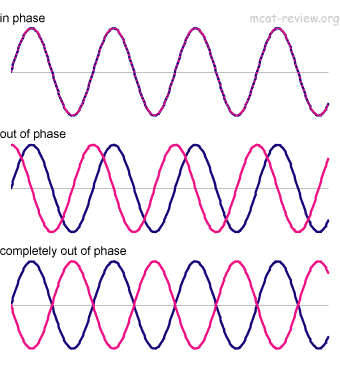
Phase一直存在于音频中,而且常常被人忽视,它是个隐藏的杀手。我们知道音频是以波形的方式传递的,而波形就意味着有波峰和波谷,在混音中,如果同一频率下出现的两个声音,它们的波峰和波谷振幅也一样,但是刚好相反,那么这两个声音会被完全抵消 ,两者的声音都会消失 – 这个现象术语称之为Phase Cancellation相位抵消。即使很难出现这种极端情况,但同一频率的两个声音,哪怕存在一点轻微的相位差,也会导致声音音量的削弱。
Phase相位现象不仅存在于混音中,录音中也广泛存在。比如用多只话筒录制一个声音,这些话筒由于电信号传递的延迟不同,就会导致它们录制的同一个声音存在相位差,这些声音合并在一起反而听起来更加虚弱。比如用同一只话筒在特定的房间内录音,直达声和反射声先后进入话筒后,也会形成相位差,造成声音空洞。在混音中,一些插件由于会产生负载延迟,也会引起之前完全可能完全不存在的相位问题。
因此,我们需要花时间去了解和理解相位,并利用如相位同步等软件在后期混音时解决这类问题。
Pan 声像
不要将声像与声相搞混. 声像Pan指的是该声音在立体声声场中的左右定位, 而声相则指声音的相位, 也就是Phase, Phase是个极为复杂的概念.
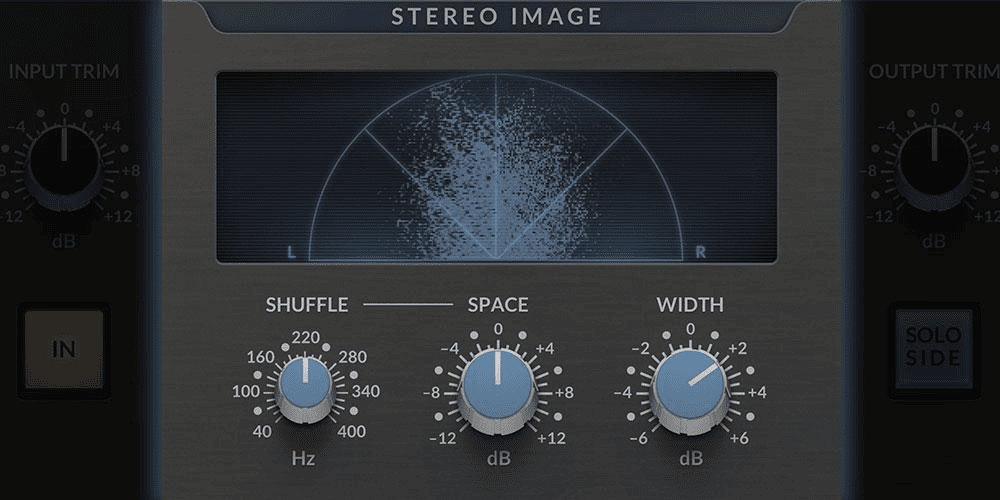
Stereo Image 立体声宽度
立体声宽度,很好理解。声音在录制中,由于立体声话筒的摆位和指向,或单声道录制的特性,声音往往并没有显现理解的空间感。我们会使用Stereo imager来改善这种状况。Stereo Image(r) 一般有两个参数,Width宽度,拉高宽度,会加强信号在左右声道两边的呈现,但会弱化信号在中间的呈现(也会带来信号变薄的感觉),降低宽度,会收窄信号在左右两边的呈现,强化中间的成像,同时提升信号的深度。另一个参数就是Shuffle 偏转,能让信号偏向某一边。注意:Pan 声像也是将信号摆放在立体声像中的某一边,但Pan并不顾及声音的相位和空间感,而Stereo Imager中的Shuffle则会利用信号的相位和空间感来创造左右的偏转效果。因此两者的效果还是有很大不同的。
Spatial Audio 空间音频
Spatial Audio 通常特指通过特殊技术以实现在立体声回放中呈现带有3D效果的听感。这点和多通道环绕声有一点区别,后者通常是将声音分配到特定位置的音箱来实现环绕声,而Spatial Audio是通过特殊的转换技术在左右声道的立体声回放中呈现更多的环绕定位。
Fader 推子

Fader 就是通道上的推杆。通常来说,Fader 主要用来控制通道、编组上的音量。在一些控制台上,推子还能切换为控制其他参数,比如声像、效果器参数等。
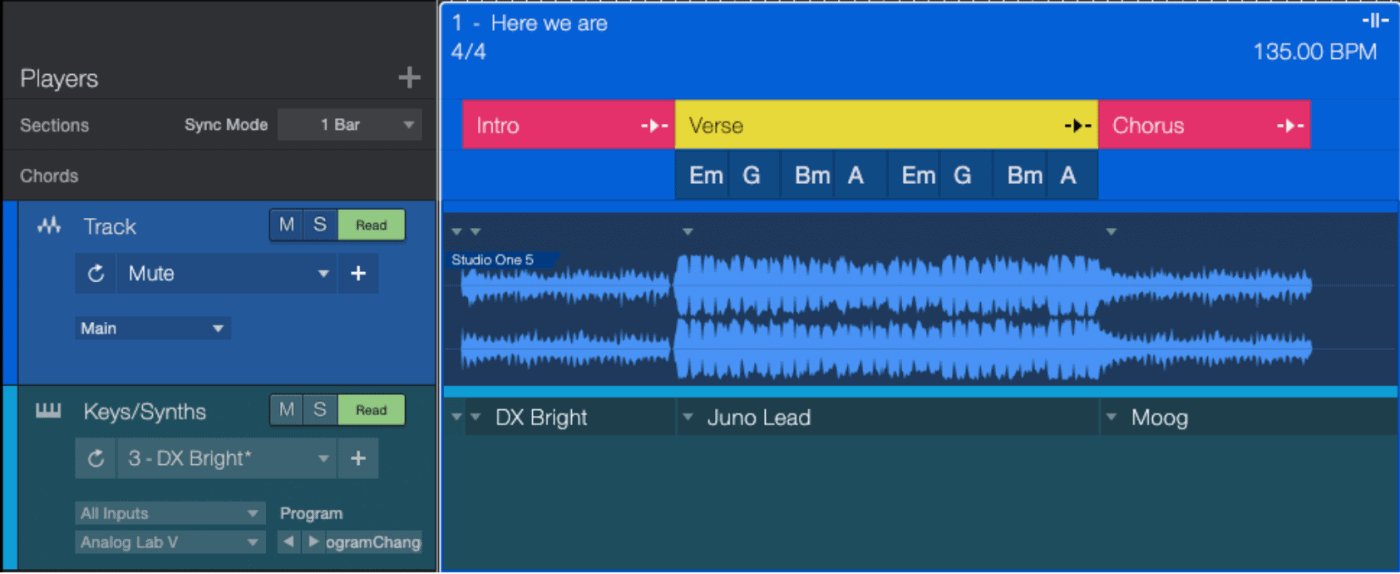
音乐类常用术语
Note 音符
我们在DAW中用任何乐器, 录入一个单音, 就是Note音符. 音符的特点是它有音高, 也有长度. 这些都可以由我们随意决定,
Key 音高/调号
音高来源于频率. 当频率高出一倍时, 在音高上听起来就高了一个八度, 于是我们将这个八度平均分为十二个半音, 用于准确的识别, 演奏旋律和记录它们. 这个八度包含从低音的基础频率到双倍频率后的高音, 我们用英文字母C-D-E-F-G-A-B-C1(高八度的英文字母用后面添加数字1表示, 高两个八度则改为2, 以此类推).
但由于每一个音符都有一个音高, 所以现代音乐创作中, 我们往往只用Key来表示一整段旋律的主音, 这时Key就作为调号, 来表示当前曲目大致的主要音域.
Sharp 升号/Flat 降号/Natural 还原号
前面说到, 一个八度用CDEFGAB, 七个字母来表示, 但问题是这个八度包含了十二个半音, 这七个字母显然远远不够. 这样, 在相邻的两个字母间我们加入升降号来填补半音的空缺. 比如C到D我们加入C#, 来代表将C升了一个半音音高, 以此类推, 结果成为了C-C#-D-D#-E-F-F#-G-G#-A-A#-B. 数一下是不是十二个? 而降号b, 则是用于将一个音符下降一个半音, 因此它和升号效果相反, 但完全可以表达相同的意思. 我们完全可以将之前的十二个半音排列标记为C-Db-D-Eb-E-F-Gb-G-Ab-A-Bb-B, 它们在音响上时完全一样的. 至于还原记号♮, 常用于我们在临时对某个音比如C进行了升降后比如C#, 需要在下一次这个音演奏时还原回来不做任何升降, 我们就标记为C♮.
注意, 如果你发现了一个问题, 那么表示你看的很仔细. 前面说到一个八度是包含了主音到高音的, 这实际上意味着八度中包含十三个半音, 即从C~C1, 但实际上八度并不包含最后的那个高音C1, 然而在大量的实际应用中, 我们常说的演奏一个八度的双音, 往往就包含了低音C和高音C1, 这主要是为了简化表达以方便交流.
Scale 音阶/Mode 调式
音阶代表着在一个八度中, 音符的发展序列. 比如我们说过的C-D-E-F-G-A-B, 不演奏那些添加在中间的半音, 这就是七声音阶, 也就是我们在键盘乐器上看到的一个八度中的白键部分. 七声音阶完全可以演奏大部分的旋律和编配. 如果你试着只演奏键盘上的C-D-E-G-A五个音, 会发现这就是我们中国民族音乐的再现, 是的, 五声音阶是中国和很多国家民族的传统音阶, 我国古代称呼这五个音为”宫商角徵羽”, 一个八度中只弹奏这五个音. 再比如我们演奏A-B-C-E-F, 你会发现一丝忍者的气息, 而这也就是日本常见音阶的一种. 音阶没有硬性规定, 你完全可以按你自己的需求定义一条新的音阶出来(问题是由各种自定义音阶固定出来的所有模式, 都已经登记入册了).
那么, 这些登记入册的音阶模式, 就被成为调式. 音乐中最主要的几大调式为, 大调式, 小调式, 五声调式.
大调式又分为自然大调, 即C-D-F-E-G-A-B-C1, 和声大调, 即C-D-E-F-G-Ab-B-C1, 旋律大调, 即C-D-E-F-G-Ab-Bb-C1. 可见大调中, 前面一半多的音阶都是自然进行的, 而仅仅在后段改变的个别音高.
小调式也分为自然小调, 和声小调, 和旋律小调. 但它的排列是从A开始, 自然小调为A-B-C-D-E-F-G-A1, 和声小调为A-B-C-D-E-F-G#-A1, 旋律小调为A-B-C-D-E-F#-G#-A1. 可以看到小调式的特点, 是音阶的前半段就出现了半音, 从A-B-C中, B-C是半音关系, 这在听感上与大调有明显的区别.
五声调式则没有大小调式这么浓郁的色彩, 但五声调式能呈现出莫比乌斯环一样的无穷无尽的效果. 在五声调式中, 音阶排列反而很重要, 在我们中国, 宫商角徵羽用来代表五声调式的不同音阶模式, 宫调式为C-D-E-G-A, 商调式为D-E-G-A-C, 依次类推.
Interval 音程/Chord 和弦
前面说过, 一个音, 就是Note. 而两个音, 则叫做音程, Interval. 音程可以是个名词, 也可以是个计量单位. 比如我们弹下两个音, C和E, 这中间包含了C-D-E的三度关系, 我们就称之为大三度音程, 也可以描述为C和E之间的音程为大三度. 再比如我们弹下A和C两个音, 它们的音程就是小三度. 音程用于表达两个音之间的音高距离, 只不过我们通常不会专门用音程这个词来表达, 或者仅仅出现在当你需要歌手演唱一个C到D2的大跨度时, 歌手可能会用这个音程跨度太大了我有点难度, 这种情况.
然而音程是用来解释很多定义的基础元素, 比如我们不演奏C和E, 而想以G为根音同样演奏出一个大三度, 我们就需要先了解C到E之间的音程关系, C到D是一个大二度, D到E又是一个大二度, 那么大三度音程, 就是填充了两个大二度的音程, 于是我们可以推算出G到A是大二度, A到B也是大二度, 因此演奏G和B两个音, 就能得到大三度音程.
而如果我们不仅仅演奏两个音, 而是三个或以上的音呢? 此时我们就用Chord和弦来表示了. 同时演奏三个音, 我们称之为三和弦, 同时演奏四个音, 我们称之为七和弦. wait….what??? 哈哈我知道你在想什么, 听我解释.
要构成和弦, 是要有基础条件的, 并不是简单的三个音就能称为和弦, 和弦的组成, 需要两个条件, 一是音程关系必须为三度, 而是这样的音程必须有两个. 也就是说, 我们需要弹奏三个相互跨度为三度的音, 才能组成一个基础的和弦, 也就是三和弦. 如果我们弹奏C, D, E三个音, 不能称之为和弦, 但如果我们弹奏C, E, G, 则就是一个标准的三和弦. 三和弦的基础上, 我们再加入一个三度音程, 就能组成七和弦. 而为什么仅仅加多一个三度音程, 三和弦就变成七和弦了呢? 这里面, 三和弦的三, 和七和弦的七, 不是一个属性的, 三和弦的三, 表示演奏三个音的三, 是数量词. 而七和弦的七, 指的是在三和弦的三个音, 即第一音C, 第三音E, 和第五音G的基础上, 添加一个第七音B, 这才是七和弦七字的由来. 当然, 我也同意你的看法, 这样的话其实三和弦还不如成为五和弦(因为演奏了第一第三第五音), 或者七和弦还不如成为四和弦(因为演奏四个音), 但我可没办法改变这个延续了上百年的传统, 另外, 三和弦七和弦的概念, 就这么一次你就能记清楚, 并不会影响你判断.
三和弦, 虽然由两个三度组成, 但这两个三度是什么三度也很重要, 如果前面的三度是个大三度比如C到E, 后面的三度是个小三度, 比如E到G, 那么这个三和弦就是大三和弦, 它的听感也是光明磊落的. 但如果我们的前一个三度是小三度比如C和Eb, 后一个三度是大三度比如Eb和G, 那么这个CEbG的三和弦, 就是一个小三和弦, 听觉上也较为暗淡. 七和弦也同样如此, 分为大七和弦, 属七和弦, 小七和弦等. 当你理解了七和弦, 会发现它几乎是当今音乐中最主要也最重要的根基, 它就像画家中的红绿蓝三原色, 可以调和出非常饱满的色彩.
Major 大调/Minor 小调
如果我们想要在纸上写出我们刚刚演奏的那个和弦, 比如C为根音的一个大三和弦, 我们显然不会写上前面这句臃肿的句子, 而只需要记录C即可, 这一个字母就代表了以C为根音的大三和弦也就是C, E, G. 如果我们在C后面加上m, 就代表这个和弦是C minor的小三和弦, 我们就知道要演奏C, Eb, G三个音. 所以, 记录三和弦最为简单, 大三和弦就写根音字母, 小三和弦加个m.
七和弦较为复杂, 因为前面知道, 三和弦仅分为大小两种, 而七和弦除了大, 小, 属外, 还有减七和弦, 减小七和弦, 这时七和弦的标记就繁琐一些,
Chord Progression
Velocity/Expression
Pattern 模板
Bar/Measure 小节/
Loop
Tempo
BPM
Signature
Quantize
Octave
Transpose
Articulation
Keyswitch
Compose/Song Writing
Structure
Intro/Verse/Pre-Chorus/Chorus/Bridge/Outro
Fill
Break/Buildup

常见经典硬件及复刻品牌
API
![]()
API是一家成立于1969年的美国公司, 全称Automated Processes, Inc(API). 创立人Lou Lindauer和Saul Walker都是精通音频工程的工程师, 他们在1967年为纽约一家录音室设计混音控制台时, 巧妙的为控制台设计了500系列, 也就是现在流通于市面的500系列. 在其控台设计与500模块化设计受到欢迎后, 二人就决定成立API公司并开始制作商业录音控制台, 在这之后, API的设备就开始闻名于世. Waves, UAD, Lindell Audio都对API的产品进行了大量复刻.
EMI
EMI, Electric and Musical Industries Ltd, 英国电子音乐工业有限公司, 也就是我们常听说的百代唱片. 实际上, 百代唱片名称源于20年代中国人对法国留声机公司Pathé的昵称, 到了30年代, 英国哥伦比亚留声机公司收购了法国百代, 改名为了EMI. 在二战时期, EMI在整个音视频设备领域都相当顶尖, 基本垄断了当时的包括BBC在内的专业电信设备. 但EMI最著名的事迹, 是建立了Abbey Road Studios, 并招募了George Martin和The Beatles乐队. 随着The Beatles的走红, EMI为Abbey Road专门制作了大量的设备以协助开发录音事业. 其中, EMI TG12345控制台, 和REDD.37和.51控制台, 及磁带录音技术ADT等技术核心, 都不断被复刻及模仿.

Universal Audio
![]()
Universal Audio 由 Bill Putnam Sr. 于 1958 年创立,自成立以来一直是创新录音产品的代名词。已故的 Bill Putnam Sr. 是 Frank Sinatra、Nat King Cole、Ray Charles 等人最喜欢的工程师,他是一位充满激情的创新者,被广泛认为是现代录音之父——他的许多传奇工作室和设备设计至今仍在使用。
具体来说,Putnam 是现代录音控制台、多频段音频均衡器和人声室的发明者,他是第一位在商业录音中使用人工混响的工程师。与他的朋友 Les Paul 一起,Putnam 还参与了立体声录音的早期开发。
Putnam 是一位天生的企业家,在他漫长的职业生涯中创办了三家音频产品公司:Universal Audio、Studio Electronics 和 UREI。这三家公司制造的设备在推出几十年后仍然被广泛使用,包括无处不在的 LA-2A 和 1176 压缩机,以及 610 电子管录音控制台。尤其是 610 调音台,它是音频史上最受欢迎的设计之一,用于录制从 Sinatra 到 Beach Boys 再到 Van Halen 的同名首张专辑。
SSL
Solid State Logic. 是由Colin Sanders于1969年成立的英国品牌, Sanders一直梦想开发一款可录音可混音, 可灵活路由, 并有记忆功能的录控台, 于是他自己做了两台, 并命名为SL 4000 A. 这段历史决定了SSL未来走向大型控台设计之路. 在1979年, SSL在George Martin的协助下开发的SL 4000 E具备了四段EQ, 混音设定的记忆和读取, 及第一次在所有轨道上集成了噪门和压缩. 到了1987年, SSL的SL 4000 G系列一炮而红, 全部卖到了美国各大录音室. G系列的总线压缩, 成为了现在最流行的传统总线压缩之一.

Fairchild
UREI
Pultec
Neve
Neve品牌是由著名的音频工程师Rupert Neve于1961年的英国创立. 1964年, Neve为伦敦的Philips录音室打造了第一台晶体管为主的控制台. 1968年, Neve的产品开始进入英国广播系统, 并进入美国市场. 1970年, Rupert为Neve A88混音台设计了1073模块, 这也成为了世界上最著名的话放前级(工作室使用的是Warm Audio产的273-EQ版). 而Neve的多个产品也反复被不同硬件软件厂家复刻. Neve于1985年被西门子集团收购, 于1992年与西门子旗下另一子品牌A.M.S进行了合并, 数字设备部分成为AMS Neve, 但模拟设备系列依然保持Neve的独立标识.
Teletronix
Empirical Labs
ELI(Empirical Labs Inc)由Dave Derr成立于1992年的美国. 显然这并不是一个很有故事的品牌, 但他们于1995年创造的Distressor压缩器, 一下子成了爆款. ELI也因此进入了经典设备名人堂…
dbx
Focusrite
Altec
Manley
Chandler
Chandler并不是一家经典的硬件品牌, 实际上它诞生于1999年. 但它经常复刻并改进一些经典的复古设备, 尤其是EMI Abbey Road系列. 这导致它也成为了软件复刻的对象.
Drawmer
Summit Audio
elysia
Avalon
Lexicon
Shadow Hills
Tube-Tech
Tube-Tech
STUDER
Studer
TASCAM
TASCAM
YAMAHA
YAMAHA
MOOG
Moog

文中脚注:
- 1常规的插件格式只有临时的短暂的数据流
- 2即音色如机器般的重复,非常缺乏真实感和戏剧性