很多朋友总是问我, 他们想制作自媒体节目, 想录制更专业的旁白, 该如何购买话筒, 又该如何进行后期制作呢? 这并非一句话就能说清楚的, 整个声音的传输, 不仅仅是话筒, 还包含了环境, 信号流和效果器, 甚至监听也非常关键. 让我来逐一说明吧.

环境 ENVIRONMENT
首先, 录制声音最基础的条件, 是环境, 因此, 全文是建立在录制时的基础声学环境还不算糟糕的情况下. 如果你的录制环境处在一个嘈杂和混乱的建筑工地, 或菜市场旁, 也许你应该先将这篇文章做个记号, 等搬完家了再回头继续. 这当然是个玩笑, 但营造好的录制环境, 是创造最佳人声的基础.
最佳的人声, 在旁白这个*语境中, 指的是干声.
*在不同的录音风格中, 对干声的需求也不尽相同. 语言类录音通常要求纯粹的干声, 而合唱录音, 往往需要混入现场的混响, 对干声的要求就不会太高, 甚至会专门录制现场的混响以加强合唱的空间感.
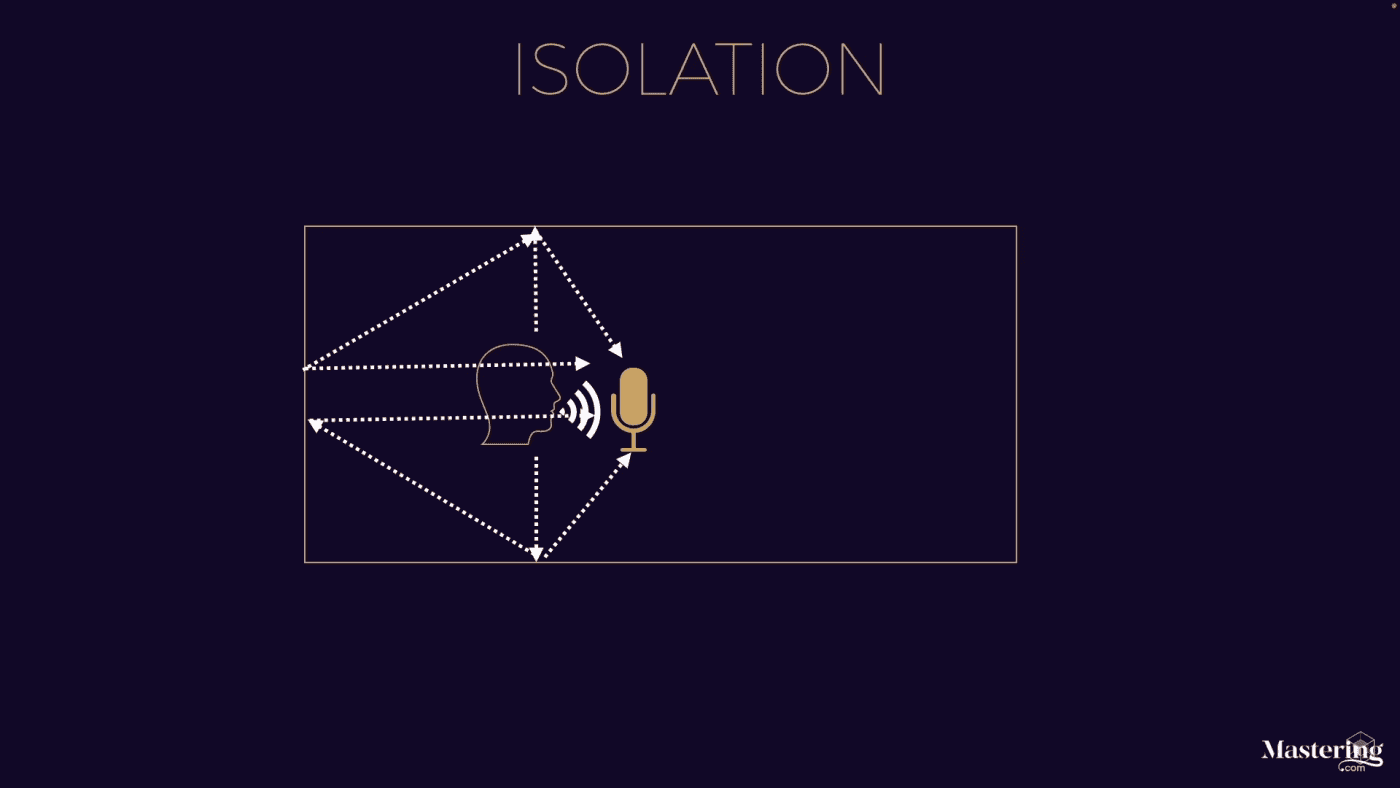
上图可以清晰的看到人声会从空间里的各个角度反射回话筒, 因此除非你需要这种反射声, 否则这些都是在干净的录音中一定要杜绝的. 在旁白类的声音需求中, 我们一般需要的是最极致的干声.
- 干声 Dry Signal
在声音录制和制作中, 干声Dry Signal和湿声Wet Signal将会是我们大量遭遇的两个词. 干声指的是(在当前阶段)不加任何效果的声音, 在旁白录音阶段, 在人声与话筒之间, 我们不允许加入空间里的其他元素, 比如混响, 反射声, 共振等等, 这样我们才能得到纯粹的干声.
- 湿声 Wet Signal
湿声指的是(在当前阶段)添加了效果器后的声音. 比如前面说到的干声不允许加入混响, 就是为了在湿声也就是效果器阶段, 能添加更合适的混响. 想一想, 如果你前期录音就已经带了一个小房间独有的混响, 后面你想加入一个另一种更漂亮的效果器混响时, 两个混响就会叠在一起变得混浊了. 因此这个理念就清晰了, 干声, 是为了提供更纯粹的素材, 给下一步湿声进行完美的无污染的效果做准备的.
- 混合 Mix
混合也会大量出现在与干声湿声相关的区域内. Mix这个词在音频领域会频繁出现, 当它出现在干湿这个语境中, 它的作用是将纯粹的干声与纯粹的湿声(效果声)进行混合, 按你的需求来调整比例. Mix也会出现在其他语境下, 比如混音器(调音台)Mixer, 混音过程(Mixing)等等.
从我们对干声极致的追求, 可以看出, 要获得干声, 我们就需要大量的改造录音环境, 因为营造隔音与吸音的环境是获得干声的前提.
- 噪音与隔音 Noise & Isolation
噪音包含了室外和室内的噪音. 室内噪音我们可以找到异响(通常是电器)并关闭, 室外噪音则需要我们对噪音传入的空隙进行隔绝以减少干扰.
入门, 我们可以将门窗关紧以最大程度隔音
进阶, 门窗可以用加厚的隔音棉覆盖, 地面添加地毯, 进一步隔音
专业, 墙面地板天花板均加装一层架空层, 填充隔音棉
- 反射与吸音 Reflection & Absorption
反射声指的是声音在发出后遇到平面弹射回来后的声波. 过于平坦的表面容易形成反射甚至多次反射, 因此我们需要通过吸音将这些反射声软化和吸收.
入门, 房间不要太大, 摆放一些家具打乱声音的直接反射
进阶, 墙面与天花板覆盖吸音棉, 进一步吸收和抑制反射
专业, 墙面地板天花板均加装架空层, 并填充吸音棉
- 消除共振 Eliminate Resonance
由于白天城市的各种机械如汽车, 空调都会造成楼体的共振以产生低频, 尽可能在夜晚进行录制. 在话筒架下方加多缓冲型的地毯地垫也有助于缓解. 同时留意房间内各种中空的大型装饰品或箱体, 如柜子和吉他之类, 这类空腔都会造成中高频共振, 可移出房间或用毛毯覆盖或内容物填充.
在做完了以上的几点后, 你可以简单的测试一下是否达到了基础的隔音. 比如你可以用手机下载一些测试SPL声压值的App, 然后在房间内运行, 以判断室内噪音等级, 如果维持在安静的办公室级别, 或40~50dB左右, 那么恭喜你, 你的一切努力都得到了巨大的成果, 这个环境不易受到外界干扰, 几乎可以(在一些后期效果的帮助下)胜任一切录制任务.
| 声源 | 声压值 Sound Pressure Level (dB) |
|---|---|
| 完全无声 | 0 |
| 树叶骚动 | 20 |
| 1米内的轻声细语 | 30 |
| 安静的办公室 | 40 |
| 1米内的正常交谈 | 60 |
| 车内 | 65-80 |
| 大声唱歌 | 70 |
| 3米左右的运行中的吸尘器 | 75 |
| 15米左右的大巴, 大卡车和摩托车 | 80 |
| 15米处的风镐 | 90 |
| 地铁车厢内 | 94 |
| 1米处的除草机 | 107 |
| 致聋, 人类听觉极限 | 120 |
| 30米处的喷气式飞机 | 130 |
| 疼痛的极点 | 140 |
| 30米处的喷气式战斗机起飞 | 150 |
| 大型军事火炮 | 180 |
而测试吸音, 你可以在房间中大力的咳嗽, 或击掌, 并与另一个房间进行对比. 如果感受到的回声明显减小, 那么你在正常音量下录制旁白, 也几乎不会受到反射声的干扰了.
OK, 当基础环境有了一定的改善(并非需要达到专业级的隔吸音, 但一定要比零改造的好), 你也预估能得到不错的干声时, 我们就可以进入到话筒的选择环节了.

话筒 MICROPHONE
首先我们要正确的挑选话筒.
分类
我们先来说说话筒分类, 话筒的主要类别为动圈话筒, 电容话筒和驻极体话筒.
- 动圈话筒 Dynamic Microphone
不需要单独供电, 内部是线圈结构, 灵敏度较低, 对声音的压力耐受度很高, 也就是说, 微弱的声音它根本不拾取, 但声音越大越好, 它很难爆音, 当然我说的是常规情况下. 这意味着它非常适合用于拾取现场歌手, 鼓, 电吉他音箱等声压巨大的声音. 不过, 稍显粗糙的收音效果谈不上精致.
- 电容话筒 Condencer Microphone
需要48v幻象供电, 内部是振膜结构, 意味着对空气中微小的震荡都能细腻的捕捉, 常用于安静的室内环境录音, 它最适合捕捉细腻的声音和气息.
- 驻极体话筒 Electret Microphone
体积非常小巧, 常用于领夹话筒和头戴式话筒. 频率响应迅速, 但较小的体积对低频响应不佳, 声压承受力也非常弱, 唯一的优势就是便携.
所以, 对于旁白话筒来说, 动圈话筒可以排除噪音, 承受住高压的喊叫, 而电容话筒声音细腻, 频率饱满, 各有优势. 但驻极体话筒显然对提升音质没什么帮助, 我们可以淘汰掉它.
指向性
接着, 话筒的另一个参数, 指向性, 指向性主要分为全指向, 心型指向, 超心型指向, 枪型指向和8字指向, 它们的区别在于基于话筒头的收音方向.
- 全指向 Omni
意味着话筒周围的360度全部在其拾取范围, 四面的声音均被收录.
- 心型指向 Cardioid
意味着以话筒正面为中心的扇形区域为拾取范围, 看起来像颗桃心, 因此称为心型指向, 一般心型指向更适合于拾取乐器和人声, 因此也是旁白话筒的首选.
- 超心型和枪型指向 Super Cardioid/Shotgun
以此类推, 是以话筒为中心而构建的一个更狭窄的拾取范围, 同样适用于人声收音, 由于拾取范围过窄, 优点是可以排斥大部分无用的背景噪音, 缺点是稍微离轴, 声音就会立即削弱或产生音染, 因此需要保持指向的时刻准确.
- 8字型指向 Figure-8
比较类似全指向, 只不过两侧会有所切除, 意在拾取话筒正反两面的声音, 更适用于合唱, 乐团或是两人共用一个话筒的情况.
因此, 在选购前, 请认准你的话筒指向指标, 心型, 超心型, 枪型指向有一定使用的区别, 但基于人声录制都处于话筒的近距离正前方, 因此都适用于人声或旁白的录制. 而全指向和8字型指向, 由于覆盖太多周边范围, 会导致拾取过多环境噪声, 并不推荐. 好在除了驻极体话筒, 大多数话筒都没有全指向(许多话筒支持多指向调节, 如AKG C414这类, 可放心选购).
振膜
接下来, 话筒的振膜.
- 大振膜 Large Diaphragm
我们常发现, 一些录音棚中歌手演唱所使用的话筒, 外型都比较大, 话筒收音头里面采用了大型的圆形振膜. 这一类通常是大振膜话筒,
- 小振膜 Small Diaphragm
也有一部分个头小巧的话筒, 用来录制乐器, 这些是小振膜话筒, 也称为铅笔话筒.
不同振膜的大小, 也导致了音色的偏重, 在指标上, 虽然大小振膜的话筒都声称可以拾取20Hz的低频到20KHz的高频, 但由于振膜的尺寸和体积不同, 导致实际应用中, 它们的频率响应还是有一定差别, 小振膜话筒反应迅速, 在拾取中高音上更清晰更有颗粒感, 且由于体积小巧, 很容易组成立体声或多声道来拾取乐器. 而大振膜能捕捉更多低频的细节, 拾取音域更宽广, 更饱满醇厚, 更适合穿透力较小, 较为柔软的乐器或人声.
其他特性
如果话筒仅仅从分类, 指向和振膜就可以轻松选出你的最佳, 那会有点太容易了. 话筒还有些独特的参数, 用来迷惑你的双眼. 比如
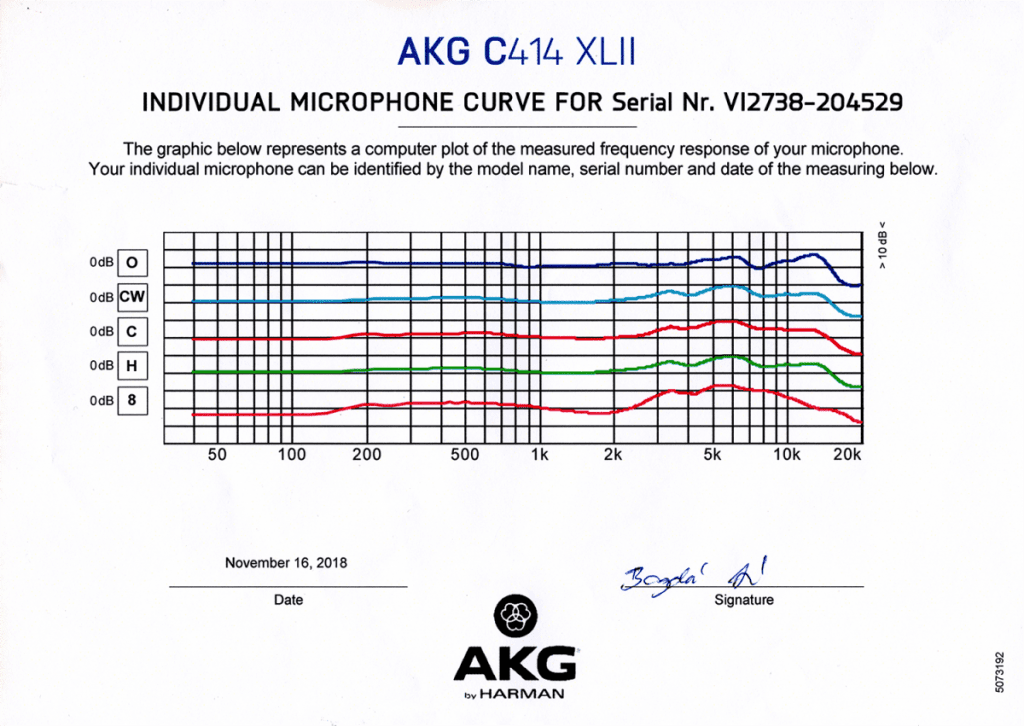
- 频响曲线 Frequency Response Curve
不同的话筒, 即使是同一个品牌, 由于其构造, 设计目的和公差, 都有不同的频率响应曲线, 也叫频响曲线. 这条横向的弯曲线条, 代表着话筒在从左(低频)到右(高频)收到空气中不同频率震动后, 对该频率的捕捉灵敏度. 有的话筒捕捉低频更好, 有些则强化高频, 有些可能会在中间挖一个小坑又在高频推起一点以美化人声. 简单的来说, 越平直的曲线最好, 这意味着朴素的还原. 不过即使是不完美的曲线, 后期也可以通过EQ效果来进行(有限的)弥补.
- 近场效应 Proximity Effect
对于大振膜话筒来说, 近场效应是其专有的一种属性. 越靠近话筒振膜, 话筒对低频的频率响应就会越发强烈. 大部分高端话筒都有80~100Hz的低切开关, 用来控制对低频的敏感. 近场效应并非简单的归纳为优点或缺点, 当录制吉他或贝斯时, 话筒太靠近琴弦, 可能会产生令人焦躁的嗡鸣声, 但如果你喜欢录制非常低沉深厚的男声, 或偶尔用来练习Beat Box(这下明白为什么BBoxer都喜欢用话筒直接堵着嘴了吧), 近场效应又会是你最好的朋友. 了解并利用这个特性吧.
- 离轴效应 Off-Axis Effect
指向性越窄的话筒, 对指向越敏感. 意味着当你稍微偏离话筒朝向时, 你的声音不论从音量上还是频率上, 都出现明显的降低或变化. 离轴效应和近场效应一样, 是话筒的设置特性, 利用好离轴效应, 不仅能降低周遭的环境噪音, 还可以通过离轴的位置, 来找到你独特的声音.
- 声压级 SPL
意味着话筒可以接收到的最大响度的声音, 这个值也是越大越好, SPL过低, 可能你离话筒喊叫一声, 声音就破了. 高昂的SPL值, 就意味着更大的动态范围(和所有影音设备一样, 动态范围越大越能容忍巨大的信号差异).
- 底噪 Noise Floor
底噪存在于任何电气设备中. 任何元器件, 电路板, 接口, 旋钮都会带来底噪. 话筒也无法幸免. 幸运的是, 得益于现在的话筒工艺技术, 大部分中高端的话筒都没有明显的本底噪音或极为微弱.
综上, 这些都是挑选话筒和应用话筒时, 需要了解的基础知识. 如果在话筒的选择上仍然无从下手, 那么一个简单的建议, 如果你仅仅是录制旁白, 且录制环境一般, 那么就选择一只常见的动圈话筒(比如SHUER SM57或SM58)等待以后再升级. 如果你精心布置了录音环境, 除了录制旁白, 还涉及到演唱等讲究细节的声音表演, 那么就挑选一只具备心型指向的大振膜电容话筒比如RODE的NT1A. 这两只话筒虽然都处于入门级, 但都是动圈及电容领域的人气之王, 也都经历了市场的考验, 好评连连, 不会出错.
任何类型的话筒都有自己独特的魅力, 在广播领域, 动圈话筒其实倍受青睐, SHUER的SM7B, Electro Voice的RE20这两只都是传奇的动圈话筒. 但在歌曲录音上, 电容话筒显然又占据了上风, 比如Neumann的U87, AKG的C414等等. 不必太过纠结, 这里提到的任何一只话筒, 都能录制出很好的声音, 况且, 你还有后期的机会.

信号流 SIGNAL FLOW
选择了话筒后, 我们需要了解话筒音频信号的传输.
| 信号流 | 录音项目 | |
| 前期 | 话筒 话放, 增益 硬件效果器 音频接口, 增益 | 策划主题 撰写方案 逐字稿 |
| 同期 | 录制 | |
| 后期 | 软件(硬件)效果器 输出 | 剪辑音频 发布 |
比如信号流分为前期和后期, 前期包括了
- 话筒 Microphone
前面已经有过介绍
- 话筒放大器 Mic Pre-Amplifier
简称话放. 最大的功能, 就是放大话筒传输的信号, 并注入电气特性, 使话筒信号饱满充沛. 话筒放大器可以是独立的硬件, 也可以是声卡内置的. 如果是独立硬件, 你需要先将话放输入与话筒连接, 继而将话放输出与声卡输入连接. 话放通常都带有48V幻象供电, 可提供给你的电容话筒. 话放提升最为明显的, 是针对动圈话筒. 由于动圈话筒的被动属性和低灵敏度, 如果想在室内使用, 就需要对它进行大量的增益, 而大部分声卡都无法提供这么强大的电力. 某些话放也带有频率调整EQ区域, 可对话筒音色进行初期调整.
*市场上也有些针对动圈话筒信号弱而专门设计的动圈话筒信号放大器, 如SE的Dynamite, KlarkTeknik的CM等等, 可以提升动圈话筒的灵敏度, 但需要借助48V供电.
- 硬件效果链 Outboard Gear Chain
在经历了话放后, 你可能还听说过硬件效果器, 比如硬件EQ和压缩之类. 没错, 模拟时代的录音, 没有强大的电脑进行声音处理, 人们不得不使用大量的硬件, 以得到音质的改变. 但由于当前这个时代, 基于电脑性能和软件效果器实在太发达了, 几乎可以完美取代硬件效果器的作用, 而且还能跳过诸多硬件效果器无法弥补的硬伤, 因此这里我们就点到为止. 如果你添置了硬件效果器的话, 信号流到这里, 根据你的需求, 可以先将话放的输出接入硬件EQ, 以获得EQ的调谐, 再由EQ输出, 接入到硬件压缩, 最后由压缩输出, 等待下一步传递. 这样就组成了一条硬件的效果链.
连接外部硬件效果器, 多数情况下都是使用的串联方式, 也就是一个接一个按先后顺序排列, 也因此成为效果链, 而这正是硬件效果器的弊端之一, 因为信号的调整是需要反复修改效果链排序的, 而硬件效果器之间的连接非常非常麻烦. 当然我们也可以用并联的方式连接硬件效果器, 是的, 这也是可行的, 但这样则需要大量的输出入接口, 这又远远超出了录制旁白所需要的投入. 而硬件效果器的最大的弊端, 是对信号品质的永久性改变.
- 音频接口 Audio Interface
简称声卡. 由于话筒, 话放或硬件效果器是模拟信号, 因此我们需要拥有一块声卡(音频接口)来接收模拟信号. 声卡的工作原理为, 将话筒或其他音频线路的模拟信号通过输入接口传递到转换芯片, 转换为数字信号(这一过程称为A/D转换或模数转换), 再通过数据线如USB发送给电脑进行录音和编辑处理并以文件形式将其保存, 同时, 为了监听回放效果, 电脑处理的数字信号又回到声卡进行数字到模拟信号的D/A转换, 通过音频接口的耳机输出或线路输出到音箱. 对于主要录制旁白而言, 一块2进2出(即2个话筒输入, 2个单声道/1个立体声输出)的声卡就足够了, 专业声卡都带有48V幻象供电给你的电容话筒, 如果你的话筒已经连接独立话放, 则不用打开48V开关. 专业声卡通常有非常好的ASIO驱动, 这种驱动可以替代你的系统默认声卡驱动, 以实现更快的数据传输, 请务必安装.
- 增益 Gain
话筒并非即插即用, 话筒的整体实力和后期调整空间, 取决于它的信号质量. 而信号质量, 则取决于增益. 话放, 硬件效果器或声卡上位于话筒接口处的旁边, 通常都有一个Gain旋钮(某些设备可能使用通用旋钮)用来控制增益. 但增益并不是直接推到底的, 前面说过, 话筒信号进入电脑要经过声卡的数模转换过程, 而声卡对输入信号的识别有个极限, 就是0db, 超过0db的信号, 数字芯片无法识别会导致出现失真和爆音. 我们不需要知道过于复杂的理论和参数, 只要记住, 话筒经过增益后的音量, 在一旁的信号电平表上, 不能超过*红灯, 且主要维持在绿灯. 这就是一个理想的信号.
*避免增益过大而冲红的最简单的方法, 就是在正式录制时与话筒的距离保持一致, 然后用巨大音量说话, 并同时调整增益, 将这种巨大音量时的信号强度控制在红灯以下, 黄灯左右. 在这之后, 除了偶尔的咳嗽和打喷嚏, 你的录制应该不会再冲红了.
在以调整好的增益进入了音频接口后, 我们就会进入DAW来进行同期录制了. 录制篇的内容将在后文中详细阐述.
录制处于信号流之中, 但并不是信号流的一员, 因为信号, 不包含内容. 了解这一点可能对你的录音帮助不大, 但理解这个概念是有用的(如同技术与创作的区别一样). 信号流只代表一条信号从头到尾所经历的硬件或软件的路由方式和因此带来的自身的变化(声音频率的变化及信号质量的强弱等等), 但信号中表达的内容(文字语句诗歌或歌曲)不在其中. 同样的, 对内容的编辑也不在其中. 录制与剪辑这个环节同样非常重要, 因此在后文会专门介绍.
假设现在录制与剪辑完成, 我们又回到了信号流, 所有对音频的操作都进入了后期, 意味着我们将使用效果器对声音进行塑形, 这个由效果器组成的后期是非线性的, 意味着你可以充分自由的调整效果器的组合排列. 后期包含
- 软件效果链 Plugin Effects Chain
软件效果链是音频后期中非常重要的一环, 如果将你前期的声音比方成一团面, 那么效果链将决定这团面是做成饺子皮, 兰州拉面, 还是炸油条. 正因为软件效果链的重要性, 我们会放在下一个环节来具体解释. 当然, 我们也可以在这里将软件效果链切换为硬件, 除了硬件效果器的一大堆弊端, 它们的使用方式是几乎相同的.
- 输出 Output
输出不光是导出为文件格式这一环节, 还包含了对声音的终极限制. 这点也会放在下一环节解释.
信号到了输出这里, 就完成了信号流的全过程. 至于后期中效果器与输出部分, 我们也会在后面继续解释, 但我们这里先解释一下录制环节.
现在, 我们可以打开录音软件或者DAW, 进行声音录制了.

录制 RECORDING
通常来说, 前期准备得当的话(还记得前面那种表格吗? 前期包含了信号流的前段, 和录音项目的准备阶段), 录音过程是非常简单的. 但也相当琐碎, 此处将是你一个人的表演. 保持平静, 准备一杯咖啡或茶, 在深夜小台灯的陪伴下, 一句句的在DAW中将稿件录制下来, 并进行基础的剪辑. 我很希望你能独享这一份宁静, 但我不得不打断你, 因为有些录制的经验我可以提前告诉你, 避免走弯路.
话筒与人体工学
- 话筒的摆放与身体状态
录制旁白最舒适的姿势是坐姿, 因为你需要长时间的读稿并要反复的对DAW进行操作, 这意味着你会在桌面待上数小时, 因此尽可能选择桌面式话筒架, 可以是卡钳式悬臂支架或是仅仅是一只小的圆底盘立架, 只要它能调节到你舒适的嘴巴高度. 另外, 录制前不要暴饮暴食, 因为接下来你会久坐, 而吃太饱你可能会制造太多噪音(你懂的). 补充一点, 垂直的坐姿, 和靠在椅背的坐姿, 声音会有明显的区别, 靠在椅背能让你身体的振动更自然的, 你的发音也能越低(这是基于我认为越能延伸低频的旁白是更好的这一点, 如果你不这么认同, 就不用理会)
- 距离与朝向控制
旁白不同于演唱, 旁白需要的是大量的贴面感, 也就是说你需要营造一种在头脑中与人对话的氛围. 还记得前面说过话筒的近场效应吗, 距离话筒越近, 越能得到细密且浓郁的中低频, 由于这种低频在日常生活中人们很少能感受到, 因而你完全可以充分利用这种近场效应创造出令人沉浸的氛围感. 你可以回忆一下几乎所有的纪录片中, 旁白的声音都是深厚而低沉的. 因此, 保持与话筒在10厘米距离内, 甚至可以更近, 只要你还记得之前说过的最大音量不要冲红即可. 话筒的朝向也并非没有讲究, 如果你慢慢调整话筒的朝向, 从指向嘴巴, 慢慢偏移到指向下巴, 你的声音会变得稍微浓厚了一些. 这是由于它会捕捉到除了口腔腔体, 还有一定的喉腔腔体的共振, 这一点点也许就能突出你声线的最大魅力.
我相信你只要改善了以上两点, 你现在已经开始沉迷在自己的声音所营造的亲切厚实的氛围中了. 事不宜迟, 我们现在就进入DAW, 捕捉下这最棒的状态.
DAW是Digital Audio Workstation的缩写, 意为数字音频工作站. 这是录音, MIDI编配与混音常用的一类软件, 也是我们录制旁白最可能会用到的软件, 接下来我会以*DAW中常见的功能为例, 来提供一些录音与剪辑中的小技巧.
*如果你所使用的录音软件不是DAW类型, 也没有关系, 你可以通过网络搜索该软件中相似的功能, 只要提及以下内容中的关键字词, 相信都能找到答案.
- 走带模式 Transport
走带模式在特定录制场合非常有用, 能极大提高录音效率. DAW中默认的走带模式, 是不管播放还是录音时, 进度线走哪儿停哪儿, 也就是说, 比方你从第10秒开始录音, 在第15秒停止, 当前的进度线就会停止在第15秒处. 当你继续播放或录音时, 就会从第15秒处继续. 但还有另一种情况, 就是某一个段落需要一口气录制, 如果感觉不对就需要原地重来, 这时候我们就需要将走带模式切换到另一种, 也就是停回起点 Return to start on stop. 这种设置下, 不论你是播放还是录音中, 只要你点击停止, 它就会回到第10秒, 等待你以更好的状态进行第二次录制. 这样你就不需要在录制了糟糕的一段话后, 需要停下来, 用鼠标找到起点的位置定位, 再进行下一次. 总之, 确定好你需要的走带模式, 找出它们在DAW中的快捷键, 灵活的切换.
- 自动插录 Auto Punch
自动插录是每个DAW都必不可少的功能. 在DAW的音序窗中, 我们可以在时间轴里拉出一个LR左右节点形成一个段落区, 然后我们随便将进度线拖到这个段落区之前的任何位置, 当我们选择了Auto Punch自动插录功能后, 此时我们再按下录音, 录音似乎根本不起作用仅仅是在播放, 但当进度线进入LR段落区时, 神奇一幕发生了, 录音开始并且在段落结束的一刹那又恢复成了播放状态. 自动插录非常适合于在一段内容中仅需要修改个别词句, 这些短期的小录制完全手动也可以, 但从我的经验告诉你, 小短句的录制, 你很可能需要大量修改录音前收录进去的键盘声(也就是按下录音的那一两下敲击声), 而且由于一旦按下录音就无法听到之前的声音片段, 你会进入过度紧绷的状态, 这时录进去的词句, 其实反而更加突兀. 如果你熟悉了自动插录, 随时在关键句子上拉出一个区域, 然后往前退一两句话, 开始录音, 并同时跟读, 直到到了关键词句, 你自然而然的顺利的完全了前后衔接的补录. 这样的完成度, 常规的录制可能要5次, 而用自动插录可能只需要2次.
- 录制为音层 Record Layers
当你按下录音键的一刹那, 就意味着一次录取的进行, 这在英文环境中也称为Takes. 我们在录制一些关键语句时, 可能会需要到非常特别的情感或口吻, 而这会花上几或十几次的录取, 也许才能得到最完美的一次. 常规录音模式下, 我们是使用的Replace或Overwrite, 即覆盖式录取, 这意味着你录取第二遍时就不得不覆盖第一遍, 以此类推, 短期内的几遍还好进行撤销以重听上一次的录音, 如果多达十几遍的录取, 你就根本无法公平的反复在多条中进行比对了. 因此, 我的建议是, 使用录音模式中的录制为音层的模式. 即你的每一次录取, 都为它建立一个音层, 被包含在当前轨道下, 无论你录制多少次, 每一个录取都有自己独立的音层, 因此你可以在这些音层之间通过solo进行各式各样的比较, 从而冷静的进行挑选, 你可以以框选的方式, 选择最好的那一条音层中最完美的一句, 拼贴到主音轨中来. 录制为音层是录音中最安全的录制模式, 当然它也是最费硬盘空间的模式(不过在你选取完最重要最完美的音层后, 你可以删除其他音层). 在某些DAW中, Layer可能也成为Lane, 但意义一样.
- 时间基准 Timebase
如果你使用的是其他录音软件, 那么可以跳过这个环节. 但大多数情况人们都使用DAW来录音, 这时候要记住, 更改你的时间基准也就是Timebase. DAW主要功能是音乐制作, 这使得它大量的时间基准, 都是以BPM(Beat per minute每分钟节拍数)来进行的, 因此我们在时间轴和走带时间上看到的, 都是以拍子和小节为基准的计数, 这对于旁白和语音类内容毫无作用, 甚至还阻碍了我们直观的看清以分秒为单位的时间信息. 因此我们需要对时间轴上的节拍基准进行修改, 改为Seconds以秒为单位.
- 标记点 Marker
迅速找到DAW中关于标记点的快捷键, 并及时的用在录音里. 在录音时, 一部分为了提高效率, 会选择将录错的字词放任不管, 继续录音直到全文结束后, 再统一修改. 事实上我也比较偏向于这种模式, 不管怎么错的, 我们都尽快的重新开始这一句, 以不中断的形式与情绪完成录音, 回头进行修补. 这要好过在每一处错误点都停下来, 从前一句开始补录. 这不但会造成频繁打断下情绪与嗓音状态的流失, 还会极其拖慢效率. 然后, 如果不进行任何标记的就这么一口气的录制下去, 回头玩大家来找茬游戏, 恐怕还不如一段段的分开录呢. 不过, 如果我们学会使用添加标记点的方法, 就能既流畅的一口气录完全文, 又能快速回溯之前的每个错误点了. 我们利用DAW中建立标记点的快捷键, 在录制开始后, 每次犯下错误, 就快速按一下标记点, 然后我们不用中断录音, 重新朗读这句话并继续下去, 回头再根据标记点的位置, 就能迅速进行剪切与编辑了.
- 交叉淡入 Crossfade
在我们对音频段落进行剪辑时, 会大量出现片段的断口, 或两个片段相交叠的情况, 这非常正常. 但你也会注意到, 某些时候我们对音频进行剪切时, 下次播放到该音频片段, 会出现短暂的爆点. 这是因为音频里的波纹是从相位0开始进行上下震动, 最后回归到相位0. 然而我们剪切时可能将音频从非0度的部分剪开, 这就会导致DAW播放到这里时, 回放音响必须以极快的速度从0偏移到当前角度, 从而产生爆点. 这时, 我们可以用Fade in淡入和Fade out淡出, 来过渡一下, 让启止的瞬间, 音响播放音量为0, 以回避这个瞬间的响动. 同样的方式我们也可以应用于交叠的音频片段中, 如果两个音频片段交叠, 就极易产生上一个音频相位角度在75度而又被新的音频以-35度盖住的情况, 这同样是爆点的来源. 你可以直接用Crossfade交叉淡入的方式, 同时淡入叠加音频的启动部分, 并淡出被覆盖音频的结束部分, 以达到完美过渡. 当然, 现在大部分DAW也默认提供了剪切时自动附加淡出入的功能, 但我们多一些对该功能来龙去脉的了解也并不为过.
完成了录制和剪辑环节, 我们再次回到信号流, 来进行后期环节中的调试, 也就是对音色的改造与塑形.

效果链 EFFECT CHAIN
旁白的音质, 除了话筒话放这些先天因素, 最能进行提升的就在于效果器. 多种后期效果按照先后顺序添加, 称为效果链, 效果链没有绝对正确的顺序, 但会因为不同的顺序而改变对声音的塑造(前面说到硬件效果器的弊端也正是如此, 但软件效果器就可以随时随地拖放而改变排序, 从而快速改变声音的化学反应). 在人声处理中, 有几个最常用的效果器.
- 降噪 De-Noise
降噪并非必须, 但大多数情况下, 如果你的录音环境一般, 也不允许花更多时间和精力对环境进行整改, 那么你很有可能录到的声音存在环境噪音和空间混响. 这些噪音和混响, 对于复杂的声音形式比如流行歌曲演唱等等并不会那么明显, 毕竟有大量的配器充斥其中. 但对于更注重讲述感的旁白, 就是最大的敌人. 因此在我们录音时, 反复监听, 如果发现有明显的噪音, 就需要加载降噪效果器了.
降噪有四种方式.
噪门模式 Noise Gate. 工作原理为对输入的声音启用带有阈值的门槛, 一旦声音低于门槛, 就关闭输入信号保持静音, 直到再次出现越过阈值的声音, 再开启放行. 这样, 分隔出响亮的人声和微弱的噪音. 不过噪门式的降噪比较机械化, 如果没有调整好参数声音会变得如切片般细碎, 因此又衍生出了第二种.
扩展器模式 Expander. 扩展器虽然也使用阈值, 但有一定的缓冲空间, 对声音与噪音的分割比较柔化, 听感上更舒适. 比如Waves公司的NS1就是一款非常优秀实用的扩展降噪器. 但无论是噪门还是扩展器, 都只是对噪音片段进行分隔, 而无法消除与人声同时并发的噪音, 而且还影响语言的连续性. 因此又有了另一种方式,
采样式降噪 Noise Profile. 录制一段纯环境噪音采样, 然后加载采样式降噪器, 如iZotope的De-Noise, 对噪音进行充分学习, 之后再延用到整段人声中, 并不断调整其他参数. 这种处理方式比噪门式又好了很多.
当然, 还有一种最最简单的方式, 就是
智能降噪, 有时候, 你不得不面对科技认输. iZotope的De-Noise和Waves公司的Clarity VX都是智能降噪的佼佼者, 而近期, 一家韩国公司Supertone最新推出的Clear, 又将智能降噪推向了新的高度. 以前的降噪都需要停下录音, 进入后期模式进行降噪和等待, 现在的智能降噪几乎已经达到了可以边录制边降噪的地步.
尽管最终我们可能都会直接使用智能降噪, 但前几种方式, 能帮助我们加深对效果器常见概念的理解, 比如门限, 阈值, 拐点等等, 这也有助于你将这类效果器应用到其他领域中. 因此我个人建议对几种方式都进行广泛的尝试. 另外, 不同的降噪方式会对音频信号的延迟产生一定的影响, 如果你寻找到了最佳的降噪方式, 可以在录音时禁用它, 在录音完成后再行开启. 而且记住, 虽然效果链可自行排列顺序以得到不同的效果, 但降噪, 始终是放在第一步的. 如果降噪产生的延迟影响到了你处理后续的工作, 那么建议你在降噪完毕后渲染出成品, 再行继续. 那么接下来我们该做什么呢?
- 均衡 EQ
用来调节频率的效果器叫做均衡器Equalizer, 统称EQ. 它通过对音频低中高各个频率的调节, 达到给声音调整亮度的作用
均衡主要有三个参数:
一是频点类型 Filter Type, 比如搁架型, 钟型, 搁架型常用于将频点之前或之后的整个频段全部提升或降低, 钟型则适用于围绕频点前后两侧的提升或降低.
二是Q值, Q值简单的说, 就是这个频点的精确度, Q值越大, 精确度越高, 所操作的频段半径就越小.
三是增益 Gain, 很简单, 它就代表着这个频点是要提升还是降低. 一般情况下, 以上的几个参数, 通常通过鼠标的点击和滚轮就可以操作了, 并不复杂.
人声中的均衡使用, 主要目的是去除音色中的混浊, 提升低频和高频的丰满度, 让声音清晰且充满细节. 对于大部分人声来说, 50Hz以下的低频没有存在价值, 它不但会导致声音的低频轰隆隆令人压抑, 还会占据整个音频的动态, 占满你的headroom(就是我们说的余量), 使整体音频死气沉沉, 因此 我们首先要将50Hz以下的低频切除. 当然, 根据你对音频的了解, 是否切除低频或做多少Hz以下的切除, 可以根据实际听觉决定的(现实中, 一般人声做80Hz以下的切除是比较常见的).
接下来, 中频频率听起来有混浊感, 我们拉低这一部分频率, 让中频变薄. 混浊感消失了不少, 声音变得通透许多.
接着是高频, 高频可以做一定量的提升, 让声音听起来口齿清晰, 更有颗粒感, 但要注意, 某些频率会产生令人不适的高频刺耳声, 比如4~6kHz左右, 这个频率我们称为齿音, 或Sibilance, 我们可以在4~6kHz的范围内, 建立一个频点, 提高Q值, 以缩小操作频段, 并进行增益以放大齿音频率的信号, 左右扫荡来寻找听起来最刺耳难受的确切频率, 比如5.8kHz, 最后将它拉低, 这样就再也不会出现刮耳朵的声音了.
*频率操作中, 有个重要的理念, 就是窄切宽提, Narrow cut, Broad boost(也称Cut narrow, boost wide). 这是一切基于真实录音来做频率手术的重要信条. 意思是, 当一段声音值得被录音时, 它肯定在听觉上主体是良好的, 主体良好的音频, 通常缺陷仅在于共鸣, 而它们也仅仅以较窄的频宽出现. 我们要做的就是压制住这些共鸣而已, 而不要伤害一个主体良好的音频, 这也是为什么切除时不用宽频处理的意义. 反过来, 以宽频的形式提升, 也是这个意味, 宽频能平等的添加频率的明暗度, 而不是激发出共鸣点. 而窄切宽提通常需要在频率操作中同时进行的, 这是因为, 共鸣点虽然突兀, 但也代表了这个声音的一部分特征, 我们在切除共鸣后, 声音会变得阴暗, 这就改变了声音的色彩, 但如果我们同时增加另一个较宽的频点, 在切除频点的附近甚至同一位置(目前大部分均衡软件都能做到), 做一定的提升, 就能巧妙的修饰偏暗的色彩. 听感上似乎没有损失, 也就没有改变声音的良好主体了. 当然, 频率操作中也有很多其他约定俗成的规矩, 比如深切浅提, 宁切勿提等等, 有些在数字录音时代其实已经过时了, 但其中的经验依然值得我们去理解.
均衡常分为图形均衡或参数均衡, 图形均衡自由度较小, 由许多推子组成, 保守但工整, 参数式均衡则更像是一张白纸, 适合做更大胆的声音尝试. 业界非常著名的Fabfilter Pro Q3, 就是公认的顶级参数式均衡, 除了常规的均衡作用, 它还能做M/S也就是中置与旁侧方式的均衡, 也支持侧链, 用其他音频来调节当前音频, 甚至还能动态均衡, 类似于压缩, 非常非常全面.
完成了均衡的调节, 接下来就是另一个重磅效果器了, 压缩器.
- 压缩 Compress
旁白不同的其他声音, 理想的旁白声, 需要一定的动态控制, 以达到音量上的饱满与绵密. 哪怕一些经过专业训练的播音员或主持人, 即使能较好的控制发音, 也无法实现声音的密度, 更别说大部分业余人士了. 但使用压缩效果, 就能很好的将声音提升到理想的饱满与绵密. 调节压缩的效果器叫做压缩器Compressor, 它的作用是通过抑制超出指定范围的音量振幅, 来控制音频的整体动态. 它类似一根肠道, 将或大或小的事物塞进去, 出来的音频音量大小均匀(这真是个完美的例子啊), 听觉效果恒定, 所以压缩也是录制旁白需要使用的第二个重要效果器.
压缩通常有几个参数,
Threshold阈值, 用来设定压缩开始工作的起始音量, 比如设定在-??db, 那么输入给压缩的音频信号一旦超过这个音量, 压缩就开始工作, 超出的音频振幅将被压缩. 那么多大的音量压缩到多小才好呢? Ratio便来做这个决定,
Ratio代表压缩的比例, 超过阈值的音量, 将按照Ratio设定的比例压缩, Ratio比越大, 音量压得越扁(Ratio一般以几个db压缩到1db的比值来设定, 旁白通常在3:1~5:1之间).
而Knee, 字面意义是膝盖, 但我们一般称为拐点, 它的作用是, 如果设置为Hard, 那么一切按前面阈值和压缩比的设定来, 没过阈值不管, 过了阈值猛干. 如果设置为Soft, 那么在接近阈值拐点的时候, 压缩比提前进行少量干预, 完全通过阈值拐点后, 压缩比再按照设定比率参与.
好了, 经过这些设定, 压缩开始工作了, 也有明显的效果, 但最开始的音似乎还是有点炸乎, 显然压缩的介入速度还不够快, 我们得加快压缩介入的速度.
Attack代表压缩介入的速度, 通常以ms毫秒来计算, Attack越快, 压缩启动的时间越快, 音量振幅还没来得及展开就被打了回去, 声音从一开始就被压的紧紧实实的.
Release则是压缩的释放速度, 设定压缩打出拳头后, 以多少毫秒的时间逐步收回. 你的声音也开始有了空间开始反弹.
在全面的设定了压缩的参数后, 音频果然变得结结实实粗细一致了, 但整个音量也更小了怎么办? 放心, 设计压缩器的人也会想到这个问题, 我们有一个选项
Gain增益, 增益的用处我们都知道了, 就是提升音频信号. 前面说过, 压缩仅仅限制超大的音量, 而不会干涉小的音量, 无形中整个音量会变小, 我们再使用Gain将整体做一个增益, 这样一来, 音量小的地方被增益了, 大的地方被压缩了, 整个声音厚重密实, 和之前飘飘忽忽的声音简直是云泥之别啊.
虽然我尽可能的用恰当或不恰当的例子来解释压缩的工作原理, 但我也知道这些参数很难几句话解释清楚, 这需要一定时间的操作和理解. 压缩系统随着品牌的不同, 还有些各式各样偏方, 就不一一赘述了. 另外, 再次重申, 音频的效果链, 除了降噪必须排在首位外, 均衡和压缩完全可以自定义排序, 不同的排序会出现不同的化学反应, 从而影响声音, 可能会破坏声音但也可能会更美化声音, 根据你的听觉感受不一而论. 你需要的是不断加深对效果器处理逻辑的理解, 在那之后, 这个音频世界就是无限的了.
- 限制 Limit
调节限制的效果器叫做限制器Limiter. 在语言录制中, 降噪, 均衡和压缩, 已经将你的声音调节得非常完美了, 但这毕竟不是全部. 最终, 你要输出这条音频还是得符合一些标准, 比如说, 不能失真, 也就是不能超过0db. 0db的概念之前在调节话筒增益时说过, 这就是数字音频的规矩, 在你修整好你的录音后, 依然要遵守这个规矩: 不得超0db. 虽然在压缩阶段, 你尽可能的控制住了大部分音频, 但始终会有那么一刻, 音频的振幅瞬间在0db以上跳动了一下, 哪怕就这么半秒的红色跳动, 你的音频输出都宣告失败, 有些DAW或录音软件还会跳出弹窗进行警告. 奇怪, 你不是刚做了压缩吗? 嗯, 压缩是个完美的振幅打手没错, 但它也有个毛病, 它出手有个Attack的速度问题, 要是真有一两个特别快的振幅瞬间冲过去, 压缩也就放它们走了. 这些偶尔出溜的失控振幅, 需要的不是一个打手, 而是一堵墙, 而限制就是这么一堵墙, 它的工作原理类似于压缩, 但是多了一个核心技术, 就是做一堵墙, 直接拦住所有冲向0db的峰值, 没有压缩比, 全部打到0db(或者是你自定义的峰值)以下. 一般情况下, 你可以设为-1db, 保留一点点空间. 限制对声音还是有再次压缩的痕迹的, 所以如果发现音量一直太满, 反复冲撞限制器, 也会带来不好的听觉感受, 你也许需要再次调整下人声, 配乐的音量, 降低限制器工作的频繁程度, 让声音不要变得过于紧密.
限制器可以直接安插在当前音频上面, 但通常情况下, 它只需要用到一次, 我们会将它安插在总输出上, 以保证不光是旁白, 包括背景音乐或音效的总和, 都能被牢牢的压在0db以下.
好, 设置完了限制器, 我们既完成了对声音的录制与剪辑, 又走完了信号流的全部流程, 是不是马上就可以输出了呢? 嗯, 事情进展到这里, 我也快编不下去了. 如果你确定没有留下任何明显的缺陷, 没错, 让我们输出吧.
不过等等, 你好像在第4分22秒处听到了一个丑陋的高音, 这一下吐字会毁了你男神的形象, 但你已经失去了全部的状态, 不想再补录了怎么办? 就这么冒险发出去么? 哈哈, 这下我又坐不住了, 让我再告诉你一个修饰声音的技巧.

修音 CORRECTION
没错, 修音. 这可能算是个额外的选项, 因为修音一般存在于歌曲演唱中的人声后期, 为了修饰音准和节奏上的瑕疵而进行的修复行为, 但旁白并非不需要修音. 要知道, 很多时候, 一个小小的断句或停顿, 或者一个尾音的下滑或上扬, 会令整个语境的气氛都变得截然不同, 甚至非常尴尬. 修音则可以完全将这些气氛控制在自己手中, 甚至连人物的声音特点, 也可以根据修音进行操控.
修音最常用的工具, 是Melodyne, RePitch也是另一个功能类似的替换工具. 由于并非所有DAW都会提供基础的Melodyne功能, 因此在这里我只简单介绍一下它对于旁白的作用.
- 音高修饰
为一段音频启用Melodyne后, 它会将该音频的声音进行分析并以确切音高的方式显示出来. 在这里, 你可以看到, 你说的每一个字其实都有音高. 你所要做的, 就是将之前那个丑陋的适当的拖拽到低一点的音高上, 同时, 切换到共振峰工具, 稍微的调节以弥补音高变化后产生的机器声效应. 经过这几下修改, 那个令人尴尬的怪声已经柔和了很多.
- 音长修饰
一旦你进入了Melodyne的世界, 你会发现原来自己的声音还有这么多可以提升的地方. 比如有些地方因为读稿, 而发出了强弱音的错乱或重点音的偏移, 我们可以通过改变音长, 将强弱音的重心再找回来. 一些没必要的拖长尾音, 我们也可以进行缩短, 反之延长.
- 齿音修饰
之前我们说过, 齿音是一个范围值而并非确切的频率, 它通常处于4~6kHz, 即便我们使用了去齿音效果器, 抑制住了6kHz, 我们的语言中可能还是会蹦出类似4kHz或3.8kHz依然让听觉难过的齿音. 这些偶然出现的齿音, 没必要再开启一个齿音效果器来去除, 因为过多的去齿音, 也会将你高频的清晰颗粒感一同带走. 我们直接使用Melodyne, 选择去齿音工具, 找到那个别几个看起来就很怪异的声音, 将它们拖动压低, 就直接物理上压制了它们. 需要注意的是, 物理上完全去除齿音, 会导致发音失去音头, 从而失去辨识度, 切勿去除齿音, 只是适当压制即可.
完成了降噪, 均衡, 压缩, 限制和修音几个关键环节的调节后, 你的旁白声已经脱胎换骨, 现在可以出街了. 不不不等等, 也许你前面的操作还有点小瑕疵, 因为你并没有真实的监听.

监听 MONITORING
人声旁白, 除了选对话筒, 调好增益, 控制均衡和压缩, 加以限制和修音以外, 能够准确的监听也非常重要. 正如不同话筒拥有不同的频率曲线一样, 耳机和音箱, 也有各自不同的频率响应曲线. 专业的监听耳机和音箱, 都有宣称的较为平直的频响曲线(但由于耳机和音箱无法绕过物理结构造成的频率不均匀及引起的复杂共振, 专业监听只能说强于普通耳机, 但依然谈不上平直). 当然, 优秀的专业监听主要用来辅助你监听到那些比较危险的频率, 比如齿音, 这种大约在4~6kHz的频率, 非常令人厌恶, 而大多数消费级耳机为了让消费者听感舒适, 会选择弱化这一频率, 这当然会让听人声变得轻松舒适, 但相应的, 一些非常优美的弦乐却也会因此失去细腻感(弦乐的弓弦声也大多集中在这个频率). 我们需要听到那些缺陷频率, 才能制作出更好的作品, 而不是回避它. 这就是我们为什么选择专业监听的目的.
- 监听
举个简单的例子, 你有一副非常棒的超重低音耳机, 用来听电音简直太震撼了, 但当你用它来处理人声频率时, 你就会觉得人声的低频过于浓重. 于是你反复的进行低切, 提高低切的频率位置, 挖去中低频那个听起来共鸣的频段等等, 直到你觉得完美并兴冲冲的发到网络上. 但第二天, 评论区就充满了”你的低频怎么都没有了?”这类的留言. 因为, 你的超重低音耳机, 对于低频是过度渲染了的, 你所以为的降低低频, 实际上是在做切除手术. 在一些具备更高级收听装置的听众耳朵里, 他们能明明白白的听清楚这些过度修饰的细节.
我的工作中也经常收到配音演员发来的文件, 他们的后期水平良莠不齐, 某些喜欢过度压缩, 另一部分则有严重的频率缺陷. 很显然, 如果他们使用了较为专业的监听, 结果会好很多. 如果你希望从一开始就培养一对拥有准确的听觉的耳朵, 并打算在录制旁白甚至音频后期之路上走得更远一点, 选择更专业并矫正过的监听耳机(监听音箱由于过于昂贵, 并非必需品)太重要了. 你可以在一些知名耳机品牌中进行挑选, 如Sennheiser森海塞尔, BeyerDynamic拜亚动力, AKG爱科技(听着跟金拱门一样土), AudioTechnica铁三角等, 观看不同产品的频率响应曲线, 并调查针对它们的评测.
- 矫正
选择了专业的监听耳机, 这几乎就完成了监听步骤中的八成了. 但我们可以将监听这一步做到完美. 我们可以通过安装一些配套监听软件(如Sonarworks Reference), 对一些知名耳机型号进行频率矫正, 以尽力恢复到平直的曲线. 如果做到了这一步, 恭喜你, 你的监听系统比世界上90%的监听系统都要准确. 监听矫正软件带来了什么优势呢? 一旦你选择了较为主流的监听耳机, 而此款耳机正好被矫正软件进行了官方的测试, 记录了频率响应并制定好了矫正曲线, 你就可以在软件中直接选择你的耳机型号, 加载这条曲线, 现在, 你的耳机就变成了打破物理机能限制的完美监听神器.
等你真正矫正了监听后, 再回头去听听你之前调节过的人声, 是不是发现到处都是雷点? 这就是没有准确监听的后果. 聪明的你一定发现了, 监听环节其实应该早早的放在文章最前面啊哈哈哈. 那些看了一半就跑的人, 会不会走上了一条错误的道路呢?

大功告成 WELL DONE!
除了文中提到的话筒, 调整和监听几大流程外, 录制旁白, 还包含了一些辅件的帮助. 比如优质的话筒线, 防喷罩和话筒架.
- 话筒线
你可以寻找可靠的店家, 进行话筒线订制. 我用过国产华真华敏的线, 自己焊接Neutrik或甬声的XLR或TRS接口, 信号也非常好. 你也可以直接购买品牌话筒线, 但不要陷入昂贵就是好的错觉. 多看看GuitarCenter, SweetWater, B&H等专业网站所卖的线材, 了解价格, 再在国内找到靠谱的代理. 国产的绿联品牌线, 便宜而且质量也非常好.
- 防喷罩
并非所有的话筒都会随品附赠防喷罩, 但这玩意可真的不能少, 尤其对于旁白录音. 旁白录音离话筒较近, 因此很多声压很大的爆破音会直接打向话筒振膜, 导致录制出砰砰的低频声. 防喷罩能几乎杜绝这种现象. 如果需要利用话筒近场效应因而更近距离面对话筒的话, 那也必须给话筒安装防喷海绵.
- 话筒架
落地式话筒架主要用于站立演唱, 而旁白则更多是坐姿录制的, 所以需要选择一款合适的桌面话筒架. 网络上虽然有很多几十元的话筒架, 但质量非常糟糕, 在拉伸移动时它们的弹簧会发出怪异的咯吱声, 过轻的负载还经常由于承受不住话筒的重要而缓降, 轻薄的材质阻止不了任何桌面上的移动声或轰隆隆的低频. 因此, 尽量选择贵一点但明显粗壮的桌面话筒架. *我的话筒架还可以挂上好几只耳机.
还有很多环节可以给旁白录制锦上添花, 比如不同的话放, 复古的均衡和压缩, 它们所提升的听觉感受, 也非常不同, 但真实的硬件也非常昂贵, 好在现在很多品牌都推出各自的复古式插件(软件), 几乎能达到同样的效果, 有机会请多尝试体验. 你也可以不断尝试打乱效果链, 先压缩后均衡, 或双压缩等等, 看看不同的组合排列所产生的独特音质. 还有很多空间类的效果比如混响, 由于旁白录制很少用到, 此处暂且跳过. 另外还有个至关重要的环节, 那就是响度, 但限于篇幅也按下不表. 最后, 一定要记得在输出上加上一堵墙, 哦不, 一个限制器, 把那些偷鸡摸狗的峰值小贼们死死的挡住.
关于旁白, 你现在是不是了解更多了呢? 如果有任何疑问, 欢迎联系我, 交流更多的问题. 从零到一, 从一到无限, 这里是smpiggy, 我们下次再见!